





Abstract
Determining star cluster distances is essential to analyse their properties and distribution in the Galaxy. In particular, it is desirable to have a reliable, purely photometric distance estimation method for large samples of newly discovered cluster candidates e.g. from the Two Micron All Sky Survey, the UK Infrared Deep Sky Survey Galactic Plane Survey and VVV. Here, we establish an automatic method to estimate distances and reddening from near-infrared photometry alone, without the use of isochrone fitting. We employ a decontamination procedure of JHK photometry to determine the density of stars foreground to clusters and a galactic model to estimate distances. We then calibrate the method using clusters with known properties. This allows us to establish distance estimates with better than 40 per cent accuracy.
We apply our method to determine the extinction and distance values to 378 known open clusters and 397 cluster candidates from the list of Froebrich, Scholz & Raftery. We find that the sample is biased towards clusters of a distance of approximately 3 kpc, with typical distances between 2 and 6 kpc. Using the cluster distances and extinction values, we investigate how the average extinction per kiloparsec distance changes as a function of the Galactic longitude. We find a systematic dependence that can be approximated by AH(l) [mag kpc−1] = 0.10 + 0.001 × |l − 180°|/° for regions more than 60° from the Galactic Centre.
1 INTRODUCTION
Star clusters are the building blocks of the Galaxy and act as tracers of stellar and Galactic evolution. With the large fraction of stars in the Milky Way formed in star clusters (e.g. Lada & Lada 2003), it is important to determine the fundamental properties of clusters such as age, reddening and mass. Determination of distance is essential to analyse these properties and the distribution of clusters throughout the Galaxy.
When a large sample of clusters is available, objects of interest such as massive clusters and old clusters near the Galactic Centre (GC; see e.g. Bonatto & Bica 2007b) become available to study. Large cluster candidate samples, such as the list based on data from the Two Micron All Sky Survey (2MASS) by Froebrich, Scholz & Raftery (2007; FSR hereafter) and others (e.g. Borissova et al. 2011; Chené et al. 2012), have become readily available in recent years. Further samples are forthcoming from large-scale near-infrared (NIR) surveys such as the UK Infrared Deep Sky Survey (UKIDSS) Galactic Plane Survey (GPS; Lucas et al. 2008) and the VVV survey (Minniti et al. 2010). Here we aim to establish an automatic method to estimate distances and reddening for such large cluster candidate samples from NIR photometry alone without the use of, or to be used as starting point for, isochrone fitting.
In a forthcoming paper (Paper II), we will extend our work and determine the ages of all clusters. We will also improve the accuracy of the distances and extinction estimates from this paper by means of isochrone fitting. That will provide us with the ability to characterize and analyse the general properties of the entire FSR sample and to investigate the distribution of ages, reddening and distances as well as their spatial distribution, observational biases and evolutionary trends. It will also allow us to extract the best massive cluster candidates amongst the FSR sample.
This paper is structured as follows. In Section 2, we discuss our selections of 2MASS/WISE data and describe in detail our foreground star counting technique as a distance estimator. We then introduce and detail our distance calibration and optimization method in Section 2.5. In Section 3, we discuss the results of our calibration and optimization method applied to the FSR list of cluster candidates and the extinction AH per kpc measurement as a function of the Galactic longitude.
2 ANALYSIS METHODS
In the following section, we will detail our homogeneous and automated approach to estimate and calibrate distances and extinction values for all FSR clusters, based on photometric archival data. Our suggested method can be applied to any large sample of star clusters and cluster candidates containing a sufficient number of objects with known distances (which will be used as calibrators).
2.1 2MASS/WISE data and cluster radii
Our distance and extinction estimates will rely on identifying the colour of the most likely cluster members. For this purpose, we will determine a membership likelihood or photometric cluster membership probability for every star in each cluster (see Section 2.2). As a first step, we hence need to specify the area around the cluster which contains most cluster members, as well as an area near the cluster which will be used as control field.
For this purpose, we use the coordinates of all FSR clusters as published in Froebrich et al. (2007). Note that this paper only contains the coordinates of the 1021 newly discovered cluster candidates. The positions of the remaining 681 previously known open clusters and 86 globular clusters are not published. For each FSR cluster, we extract NIR JHK photometry from the 2MASS (Skrutskie et al. 2006) point source catalogue. All sources within a circular area of 0| $_{.}^{\circ}$|5 radius around the cluster coordinates are selected, as long as the photometric quality flag (Qflg) was better than ‘CCC’. Typically, between 50 and 70 per cent of all stars in the catalogue have a Qflg better than ‘CCC’ (C-sample hereafter). Furthermore, about 35–45 per cent of all stars have a Qflg of ‘AAA’ (A-sample hereafter), i.e. are of the highest photometric quality. Thus, the C-sample contains on average about 1.5 times as many stars as the A-sample.
We define as cluster area (Acl) everything in a circular area around the cluster centre within F times the cluster core radius. In our subsequent analysis, we will vary the value of F between 1 and 3. The control area (Acon) for each cluster will be a ring around the cluster centre with an inner radius of five times rcor and an outer radius of 0| $_{.}^{\circ}$|5.
Note that the star density profile used has no tidal radius and thus in principle results in an infinite number of cluster stars. However, if we assume that outside five core radii (the control field) there are no member stars, then the region within three core radii contains about 70 per cent of all cluster members. If all cluster stars are contained within three core radii, then 70 per cent of the cluster members are found closer than two core radii from the centre.
In addition to the 2MASS NIR photometry, we also utilize mid-infrared data from the WISE satellite in order to estimate the colour excess of cluster stars and hence the extinction (see Section 2.8). We obtain all sources from the WISE all-sky catalogue (Wright et al. 2010) within three times the cluster core radius. The WISE all-sky catalogue is cross-matched to 2MASS; hence, we can easily identify the stars in both, the A- and C-samples, that have a WISE counterpart.
2.2 Photometric cluster membership probabilities
In order to estimate the typical colour of cluster members for our analysis, as well as to identify potential foreground and background stars to determine the distance, we require some measure of membership likelihood for every star in a cluster. We base our calculation on the well-established NIR colour–colour–magnitude (CCM) method outlined in e.g. Bonatto & Bica (2007a) and references therein. Based on earlier simulations, e.g. in Bonatto, Bica & Girardi (2004), Bonatto & Bica (2007a) note that using the J-band magnitude, as well as the J − H and J − K colours from 2MASS photometry, provides the maximum variance among cluster colour–magnitude sequences for open clusters of different ages. Since our sample will most likely contain clusters of all ages, we thus use the same colours for our analysis.
All confirmed clusters and cluster candidates in the FSR list are selected as spatial overdensities. Our photometric cluster membership probabilities are based on ‘local’ overdensities in the above-mentioned CCM space. Thus, we need to establish where these overdensities are in CCM space and if these overdensities are in agreement with the expectation for a real star cluster. Bonatto & Bica (2007a) use a small cuboid in CCM space to determine the overdensities and the related photometric membership probabilities, where the dimension of the J-magnitude side length of the cuboid is larger than the side length of the colours. Instead of a small cuboid, Froebrich et al. (2010) use a small prolate ellipsoid in the specified CCM space, where the dimensions along the J-band magnitude are larger than those along the colours. Note that the actual shape used to determine the local overdensity in CCM space (cuboid, ellipsoid, or else) is unimportant for the identification of the most likely cluster members.
Due to statistical fluctuations in the number of field stars in the control and cluster area, the above equation can in principle lead to negative values. We thus set any negative |$P^i_{\rm cl}$| value to zero and note that |$P^i_{\rm cl}$| is in principle not a real membership probability. However, all we require is a list of the most likely cluster members, which are reliably identified by this method. Note that after our calibration (see Section 2.5.3), the sum of all |$P^i_{\rm cl}$| values equals the total excess of stars in the cluster field compared to the control field. Furthermore, the sum all |$1 - P^i_{\rm cl}$| values equals the number of field stars. Thus, this membership-likelihood index can be treated as a probability. Hence, we will refer to |$P^i_{\rm cl}$| as the photometric cluster membership probability of star i hereafter.
Following Froebrich et al. (2010), we refrain from applying this method for several reasons.
In dense clusters, the probabilities are unreliable due to crowding near the centre.
For clusters projected on to a high background density of stars, the |$P^i_{\rm pos}$| values tend to be very low. This makes the cluster not stand out from the background stars in many cases, even if cluster stars have very different colours compared to the field population.
Our sample will contain a number of young clusters which do not appear circular in projection. Thus, the position-dependent membership probabilities cannot be determined by equation (4).
We hence only use the |$P^i_{\rm cl}$| values to identify the most likely cluster members.
Note that the individual photometric cluster membership probabilities are a function of the ‘free’ parameters in our approach. Hence, |$P^i_{\rm cl}$| will depend on the sample of stars (A- or C-sample) used, the cluster area Acl (between one and three cluster core radii) and the nearest neighbour 10 ≤ N ≤ 30 chosen in the CCM distance calculation. We will discuss this in detail in Section 2.6.
As an example of how our method performs, we show in Fig. 1 several diagrams for the cluster FSR 0233. Different coloured symbols in the graphs indicate the various photometric cluster membership probabilities for the stars determined for the A-sample within two cluster core radii and for N = 15. The top row shows the colour–colour diagram (CCD, left) and colour–magnitude diagram (CMD, right) of the cluster region. In the CMD, one can clearly identify that the high-probability cluster members form the top of a main sequence and a clump of red giants, suggesting an older cluster. Indeed, this is the known open cluster LK 10, which is about 1 Gyr old and relatively massive (Bonatto & Bica 2009). In the bottom panels, we show the spatial distribution of the cluster stars. In the left-hand panel, we only include stars with a membership probability above 60 per cent, while in the right-hand panel we only plot the remaining low-probability members. One can clearly see that the low-probability members, which are the most likely field stars, are distributed homogeneously in the field. In the left-hand panel, one can identify an increase in the density of stars, slightly off-centre, that indicates the cluster centre.
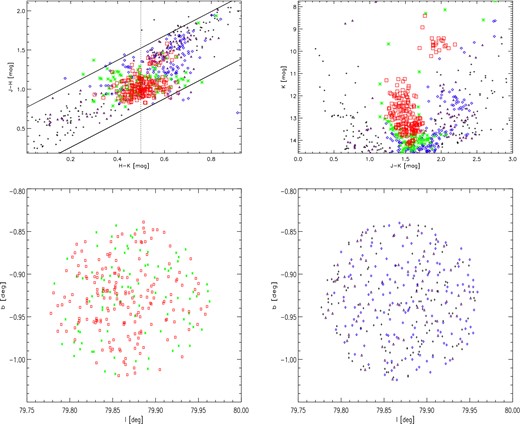
Diagrams of all A-sample stars within two cluster core radii for FSR 0233. The various symbols represent the cluster membership probabilities determined for N = 15: |$P^i_{\rm cl} > 80$| per cent – red squares; |$60 \le P^i_{\rm cl} < 80$| per cent – green stars; |$40 \le P^i_{\rm cl} < 60$| per cent – blue diamonds; |$20 \le P^i_{\rm cl} < 40$| per cent – purple triangles; |$P^i_{\rm cl} < 20$| per cent – black plus signs. The top row contains the colour–colour (left) and colour–magnitude diagram (right). The vertical solid line in the left-hand panel represents the HKmed value (0.50 mag) determined for the cluster (see the text for details). In the bottom row, we plot the positions of the stars with a photometric membership probability of more (left) and less (right) than 60 per cent.
2.3 Identification of foreground stars
For our distance calculation, it is not sufficient to solely identify the most likely cluster members. We further need to establish the most likely foreground stars to the cluster.
We utilize the median colour of the stars with the highest cluster membership probability to separate foreground and background objects. The notion is that stars bluer than the median colour of the cluster members are likely to be foreground and objects redder than this are most likely to be background.
The combination of 2MASS and WISE allows us, in principle, to use a variety of colours for this selection. However, ideally the colour with the smallest spread amongst the spectral types and luminosity classes should be used, since any reddening can then be attributed to interstellar extinction. The ideal choice would be the difference between the 2MASS H band and the 4.5 μm WISE band (H − [4.5]), since its intrinsic value is almost independent of the spectral type and/or luminosity class (Majewski, Zasowski & Nidever 2011). However, due to the low spatial resolution of WISE, only a fraction of all 2MASS sources in each cluster are actually detected unambiguously in [4.5]. We hence use (H − K) for the purpose of foreground star selection, but refer back to (H − [4.5]) in the extinction determination (see Section 2.8).
We note that for particular cases, where cluster members are intrinsically red, such as embedded clusters or clusters behind multiple layers of foreground extinction, this method will not lead to the correct number of foreground stars. The same applies if there are intrinsically hot/blue stars in the cluster area. Furthermore, photometric scatter will influence the number of blue objects. However, our calibration procedure (see Section 2.5) will statistically adjust for this.
2.4 Determination of cluster distances
The above-determined projected number density of foreground stars towards each cluster can be used to estimate the distance, by comparing this number to predictions from models for the distribution of stars within the Galaxy. Our model of choice is the Besançon Galaxy Model (BGM) by Robin et al. (2003) and we utilize its web interface1 to simulate the foreground population of stars towards all our clusters.
We use the default settings of the BGM, i.e. no clouds and 0.7 mag of optical extinction per kiloparsec distance. The photometric limits (completeness limit and photometric uncertainties as a function of brightness) in the 2MASS JHK filters are determined for each cluster and sample (A and C) separately in the control field area. After initial tests with the above settings, we perform simulations for each cluster position for an area large enough to contain a total of about 5000 simulated stars. This ensures that the uncertainties of our inferred distances are not dominated by the random nature (or small number statistics) in the model output.
The list of stars returned by the BGM simulation for the field of the cluster is sorted by distance. With the known area of the simulation, we are hence able to determine up to which distance model stars need to be considered to result in a model star density equal to our determined foreground density for the cluster. Henceforth, we will refer to this distance to the cluster as the model distance, dmod.
2.5 Calibration of cluster model distances
The model distances determined above are not necessarily accurate without further calibration. Foster et al. (2012) have shown that distances estimated from foreground star counts to dark clouds with maser sources agree with maser parallax measurements in most cases. Ioannidis & Froebrich (2012) have used a similar approach to that used by us to measure distances to dark clouds with jets and outflows. They used objects of known distances from the Red Midcourse Space Experiment Source survey by Urquhart et al. (2008) to calibrate their distances, which resulted in an accuracy for the distances that resembled the intrinsic scatter of the calibration objects.
For the FSR star cluster (candidates), the situation is more complex. Typically, the objects are not associated with dark clouds; hence, the separation of foreground and background objects (via median NIR colours) is less certain. Furthermore, crowding in the cluster (and partly even in the control field) will influence the observed foreground star density. Finally, it is unclear which parameter values used to determine the model distance dmod lead to the most accurate results.
Thus, we use sets of calibration samples of star clusters, a number of corrections to the observed foreground star density and a parameter study to investigate the accuracy of our method. In the following section, we detail our calibration approach.
2.5.1 Cluster calibration samples
As in Ioannidis & Froebrich (2012), we aim to have a cluster calibration sample (CCS) that consists of objects of a similar nature to the targets whose distance we are aiming to determine. Hence, ideally we would use a subset of the FSR clusters which have accurately determined distances.
There are three obvious choices: (i) CCS 1 – the sample of old open FSR clusters investigated by Froebrich et al. (2010); (ii) CCS 2 – known FSR clusters that have a counterpart in the WEBDA2 data base by Mermilliod (1995); (iii) CCS 3 – FSR cluster counterparts with distances in the online version3 of the list of star clusters from Dias et al. (2002).
All three of these samples have their obvious disadvantages. Both CCS 2 and CCS 3 are constructed from literature searches. The cluster distances in these samples are determined by various methods and are hence inhomogeneous. Thus, it is impossible to estimate the intrinsic scatter of the distances of the sample clusters. CCS 1, on the other hand, has homogeneously determined distances (with a 30 per cent scatter; Froebrich et al. 2010) but consists almost exclusively of old star clusters. The full FSR sample, however, should contain a mix of young, intermediate-age and old objects and it is unknown if there are systematic differences if our method is applied to clusters of different ages.
Thus, we use two of the cluster samples to test and calibrate our distance calculation method: (i) CCS 1 – the old FSR clusters from Froebrich et al. (2010); (ii) CCS 2 – the FSR counterparts in WEBDA, since this catalogue generally includes only high-accuracy measurements compared to the list from Dias et al. (2002), which is more complete.
The old FSR sample contains 206 old open clusters. We remove every object that is a suspected globular cluster (e.g. FSR 0190, Froebrich, Meusinger & Davis 2008a; FSR 1716, Froebrich, Meusinger & Scholz 2008b), which has less than 30 stars within one core radius, and/or less than 30 stars in the control field (the latter two conditions are for the A-sample of stars). We also remove any cluster with a core radius of more than 0| $_{.}^{\circ}$|05. This selection leaves 115 old open clusters in the CCS 1 sample.
We cross-match the entire FSR list with all entries in WEBDA. We consider the objects as a match, if there was exactly one counterpart within 7.5 arcmin. In the case where two FSR objects are near the same WEBDA entry, the objects are removed. We also require that every WEBDA match has a distance, age and reddening value. Finally, as for CCS 1, we remove objects with less than 30 stars within one core radius, less than 30 stars in the control field (for the A-sample of stars) and a core radius of more than 0| $_{.}^{\circ}$|05. The final CCS 2 sample after these selections contains 241 clusters.
The two CCSs have different properties which we will briefly discuss here. The majority of clusters in CCS 1 are between 1 and 4 kpc distance, but there are a number of objects that are up to 8 kpc or further away. In contrast, CCS 2 contains mostly clusters which are less than 3 kpc distant, with very few objects more than 5 kpc away. The reddening distribution of CCS 1 is biased towards low-AV clusters. The number of objects declines steeply with increasing extinction, and there are almost no clusters with AV > 4 mag. The CCS 2, on the other hand, has a homogeneous distribution of AV values between 0 and 3 mag. Again, high-extinction clusters are rare in the sample. However, the biggest difference between the two samples of calibration clusters is the age distribution (see Fig. 2). While in CCS 1 almost all clusters are about 1 Gyr old (within a factor of a few), CCS 2 shows a more homogeneous distribution of ages between 10 Myr and a few Gyr.
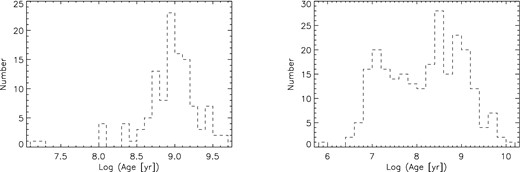
Left: histogram of the age distributions of CCS 1 – old FSR clusters. Right: histogram of the age distributions of CCS 2 – WEBDA counterparts of FSR clusters.
2.5.2 Measuring calibration accuracy
2.5.3 Crowding and extinction correction
There are a number of factors that we use to determine the model distance to the cluster which will alter the measured foreground star density (see Section 2.3). These are large-scale foreground extinction and crowding (in the general field and the centre of the cluster). Both effects are not considered by the BGM, but can in principle be corrected for.
This factor also addresses related differences in the completeness limit which is used in the BGM simulation for the cluster, but has been estimated in the control area.
2.5.4 Position-dependent corrections
With the observed foreground star density corrected for crowding and large-scale extinction, we can estimate the model distance, dmod, and compare to the literature distance, dlit, of the CCSs to investigate the scatter S of the distribution of the logarithmic distance ratios for all clusters in each CCS.
We investigate if there are any obvious correlations of the value of R with cluster parameters that are known or can be estimated for every cluster (candidate) in the FSR sample. These include the Galactic position (l and b), the apparent radius, the control field star density and the extinction (based on HKmed; see Section 2.3).
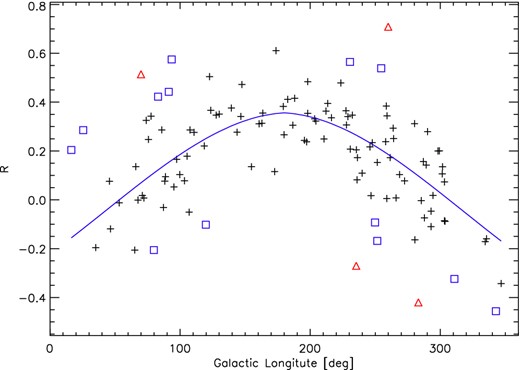
Plot of R versus the Galactic longitude of the CCS 1 objects. These are based on distance calculations using the A-sample, a cluster radius of 1 × rcor and a nearest-neighbour number in the photometric decontamination of N = 25. The solid line indicates our third-order polynomial fit. The black crosses represent points used for the fit with 2σ clipping, the blue squares represent clusters that were excluded at the 2σ level and the red triangles represent clusters excluded at the 3σ level.
We then determine the scatter Scal from the rms of the Rcal values to quantify the accuracy of our calibration procedure. In Fig. 4, we show an example of the improvements the calibration makes to the distance estimates.
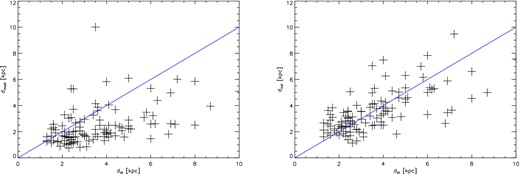
Example plot of the literature distances dlit for CCS 1 clusters (black crosses) against our uncalibrated model distance dmod (left) and the calibrated model distances dcal (right). The calibration used the A-sample, a nearest neighbour in the photometric decontamination of N = 25 and a radius of 1 × rcor. We overplot the 1:1 line in both cases. The final scatter Scal corresponds to a 40 per cent uncertainty in the calibrated distances.
We investigate if this calibration indeed removes the apparent dependence of our calculated distances on the specific galactic model used. For this purpose, we compared the distances obtained from the BGM (Robin et al. 2003) with values estimated by using the TRILEGAL4 model from Girardi et al. (2012, 2005). Distances from the latter model are obtained in the same way as described in Section 2.4 for the BGM. In Fig. 5, we show one example of a comparison of the two model distances dmodel obtained for the CCS 1 sample of clusters. The two distances depend linearly on each other, i.e. the TRILEGAL model predicts distances which are a factor of about 1.3 larger than the distance from the BGM. However, since this is a linear relationship, our calibration described above will entirely remove this difference. If we would use the TRILEGAL model, our calibration would simply result in a slightly different value for the parameter C1 in equation (10). This shows that our calibration procedure removes any systematic dependence on the specific galactic model used, since every other model will behave in a similar way. Thus, our distances are model independent. We further note that the scatter in Fig. 5 is only 5.5 per cent, i.e. much smaller than the final uncertainty of our distances (see Section 2.6). Hence, the contribution of the galactic model to the statistical noise of our method is negligible.
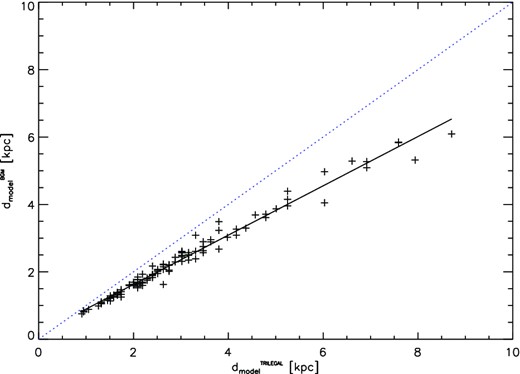
Comparison of model distances dmodel obtained from the BGM and the TRILEGAL model. The crosses indicate our calibration clusters from CCS 1. All distances are estimated for the A-sample of stars, a nearest-neighbour number in the photometric decontamination of N = 25 and a radius of 1 × rcor. We overplot a blue dotted one-to-one line as well as a black solid linear fit to the data.
2.6 Optimization of distance determination
The above-described corrections and calibrations are performed for each combination of the ‘free’ model parameters. Hence, we repeat the calibration procedure for the A-sample and C-sample of stars, the two sets of CCSs, cluster areas from one to three core radii and the nearest-neighbour number (during the membership probability calculations) from 10 to 30.
For each set of free parameters, we determine the scatter Scal to identify the parameter set that leads to the best calibration, i.e. the lowest scatter. Here we briefly discuss the results and implications of this optimization exercise.
Photometric samples. For CSS 1 there is a noticeable overall lower value for the scatter Scal for the A-sample compared to the C-sample, the actual size of which depends on the other parameters. However, for CSS 2 there is no significant change in the scatter Scal between the A-sample and the C-sample, independent of other parameter values. As the aim of our project is to find a method of distance determination for a homogeneous data set of clusters, we choose the A-sample for our calibration and the final distance calculations.
Photometric decontamination. The nearest-neighbour number N used in the determination of the membership probabilities generates no trends or significant differences in the scatter Scal for CSS 1 and CSS 2. In other words, if we only vary N and keep all other parameters the same, the scatter Scal randomly fluctuates by a few per cent, much less than the variations caused by changes in one of the other parameters. This shows that the decontamination procedure is independent of this parameter value (in the investigated range of 10 ≤ N ≤ 30) for our calibration samples. This is understandable since N only determines the resolution with which we can identify potential cluster members in CCM space (as discussed in Section 2.2) and has no influence on the colours of the most likely members which is used to determine the distances. To avoid any random fluctuations due to the choice of N (even if small), we hence choose two values for this parameter (N = 15 and 25) for the distance calculations.
Cluster area. We vary the radius of the cluster area between one and three times rcor. As for the choice of N, we find that there is no significant variation of the scatter Scal with cluster area. However, due to the nature of the star density profile (Section 2.1), the majority of cluster members will be within 1 × rcor, most cluster members will be within 2 × rcor and the additional stars between 2 and 3 × rcor will be most likely field stars. Therefore, we only use 1 × rcor and 2 × rcor in the calibration and final distance calculation.
Cluster calibration samples. We spilt CCS 2 into ‘old’ (log(Age[yr]) ≥ 8.5) and ‘young’ (log(Age[yr]) < 8.5) subsets, CCS 2o and CCS 2y, respectively. We then use these to investigate if/how the scatter Scal varies with the mean age of the calibration sample. We find that there is no statistically significant change in Scal produced by CCS 2 and CSS 2o. However, the scatter produced by CSS 2y randomly fluctuates depending on the other parameters. Additionally, there is an overall increase in the scatter when using CCS 2y compared to the entire CCS 2 sample. This could be due to the fact that a younger cluster sample, such as CCS 2y, will contain clusters which have a high fraction of young stellar objects (YSOs) with high K-band excess. These stars could result in an inaccurate determination of HKmed (see below in Section 2.7), and thus an erroneous number of foreground stars which in turn can lead to a higher scatter in the calibration. Therefore, our calibration should be applied to either a sample with a range of ages or an older sample. We choose CCS 1, as it gives consistently a smaller scatter Scal compared to CCS 2. Based on the above discussion, all determined distances for clusters with a large fraction of YSOs should be treated with care.
In summary, we find that the A-sample of stars in conjunction with CCS 1 leads consistently to the smallest scatter for the distance calibration. We find no significant or systematic influence of the radius of the cluster area or the nearest neighbour in the photometric decontamination on the quality of our method.
We therefore choose four different sets of parameter values to determine the distance to all FSR candidate clusters. The parameter values and the corresponding scatter Scal for CCS 1 and CCS 2 are listed in Table 1. The final distance for each cluster (listed in Table A1 in Appendix A) is then determined as the median of the four distances from these calibration sets utilizing CCS 1. The typical scatter and hence the accuracy of our distance calculation is better than 40 per cent, considering the intrinsic scatter of 30 per cent for the distances of the calibration sample (Froebrich et al. 2010).
Scatter Scal (per cent) of the four selected calibration sets for CCS 1 and CCS 2. All calculations are done with the A-sample of stars. The final cluster distances are determined as the median of the four distances determined using the calibration for CCS 1. N lists the nearest-neighbour number in the photometric decontamination and ‘Radius’ the distance out to which stars are included into the cluster area.
| N | Radius | Scal (CCS 1) | Scal (CCS 2) | |
|---|---|---|---|---|
| (rcor) | (%) | (%) | ||
| Set 1 | 15 | 1 | 36 | 54 |
| Set 2 | 25 | 1 | 37 | 50 |
| Set 3 | 15 | 2 | 40 | 55 |
| Set 4 | 25 | 2 | 46 | 56 |
| N | Radius | Scal (CCS 1) | Scal (CCS 2) | |
|---|---|---|---|---|
| (rcor) | (%) | (%) | ||
| Set 1 | 15 | 1 | 36 | 54 |
| Set 2 | 25 | 1 | 37 | 50 |
| Set 3 | 15 | 2 | 40 | 55 |
| Set 4 | 25 | 2 | 46 | 56 |
Scatter Scal (per cent) of the four selected calibration sets for CCS 1 and CCS 2. All calculations are done with the A-sample of stars. The final cluster distances are determined as the median of the four distances determined using the calibration for CCS 1. N lists the nearest-neighbour number in the photometric decontamination and ‘Radius’ the distance out to which stars are included into the cluster area.
| N | Radius | Scal (CCS 1) | Scal (CCS 2) | |
|---|---|---|---|---|
| (rcor) | (%) | (%) | ||
| Set 1 | 15 | 1 | 36 | 54 |
| Set 2 | 25 | 1 | 37 | 50 |
| Set 3 | 15 | 2 | 40 | 55 |
| Set 4 | 25 | 2 | 46 | 56 |
| N | Radius | Scal (CCS 1) | Scal (CCS 2) | |
|---|---|---|---|---|
| (rcor) | (%) | (%) | ||
| Set 1 | 15 | 1 | 36 | 54 |
| Set 2 | 25 | 1 | 37 | 50 |
| Set 3 | 15 | 2 | 40 | 55 |
| Set 4 | 25 | 2 | 46 | 56 |
2.7 Identification of YSOs
We aim to identify and determine the fraction of YSOs (Yfrac) in each cluster candidate. This is vital for the determination of the extinction values (see Section 2.8), since disc excess stars can potentially lead to an overestimate of the colour excess and thus the wrong extinction. Furthermore, clusters with a significant fraction of YSOs are young. Thus, Yfrac is also an important age indicator for the cluster. For each cluster candidate, the Yfrac calculation (as described here) is repeated for every calibration set as described in Section 2.6.
Similar to the HKmed determination (Section 2.3), we calculate Yfrac for the top 25–45 per cent of the highest probability member stars, in 5 per cent increments, i.e. five Yfrac values are determined for each cluster and calibration set. The final value for Yfrac listed in Table A1 in Appendix A is the median of the individual YSO fractions averaged over the four calibration sets.
If Yfrac is a negative value, i.e. there is less than one YSO in the cluster, the YSO fraction is set to zero.
2.8 Extinction calculation
In addition to distance, we aim to determine the extinction to all FSR cluster candidates using the colour excess of the most likely cluster members we identified in Section 2.2. As for the determination of the fraction of YSOs in the cluster (Section 2.7), the extinction calculation (as described here) is repeated for every calibration set as described in Section 2.6. The final extinction value for each cluster candidate as quoted in Table A1 in Appendix A is the median of the four individual extinction values.
For our calculation, we utilize two different colours.
(H − K), which we used in Section 2.3 to identify foreground stars. The (H − K) colour is less well suited to determine the extinction, since its intrinsic value for stars depends on the spectral type as well as the luminosity class of the object. Generally, this colour can range from 0.0 mag for A stars to 0.4 mag for the latest spectral types (excluding rare OB stars and L-type brown dwarfs). More typical average colours for our observed clusters are between 0.1 and 0.3 mag. The advantage of the (H − K) colour is that we can determine it for every star in the cluster area.
(H − [4.5]), which we estimate from the combination of WISE and 2MASS. The intrinsic (H − [4.5]) colour is almost independent of the spectral type and luminosity class (Majewski et al. 2011) since it measures the slope of the spectral energy distribution in the Rayleigh–Jeans part of the spectrum. Hence, it has a well-defined zero-point. However, due to the lower resolution and depth of WISE, we can determine this colour only for about half the stars in the cluster area.
Since both utilized colours use the H band, this is the natural pass band we determine the extinction in.
This method will naturally overestimate the extinction for clusters with an enlarged population of YSOs and hence disc excess emission stars. The excess colour in these cases is caused by warm dust in the disc and not foreground extinction. We identify clusters for which this may be an issue via the fraction of intrinsically red sources in the NIR CCD (see Section 2.7). We consider all clusters with Yfrac above 10 per cent as YSO clusters. These objects are excluded from the statistical analysis in this paper, but note that the fraction of such clusters in the FSR sample is rather low (see Section 3.2).
3 RESULTS
Our calibration and optimization procedure requires that for each cluster there are at least 30 stars in the A-sample within one cluster core radius and that the core radius is smaller than 0| $_{.}^{\circ}$|05 (Section 2.2). We further exclude all known globular clusters and clusters where the distances from the four calibration sets (see Section 2.6) scatter by more than 3σ compared to the average cluster. These requirements result in 1017 FSR objects being excluded, of which 931 are open clusters or candidates.
We determine the distance to 771 of the FSR objects, i.e. 43 per cent of the entire FSR sample, of which 377 are known open clusters and 394 are new cluster candidates. Based on the total numbers of these objects in the FSR list (681 known clusters and 1021 new cluster candidates), these are 55 and 39 per cent, respectively. This reflects the fact that in comparison to the new FSR cluster candidates, the known clusters should have, on average, more members and hence will more likely pass our selection criteria. The new FSR cluster candidates are typically less pronounced and a fraction of about 50 per cent of them might not be a real cluster (Froebrich et al. 2007). This has also been confirmed by the analysis of spatially selected subsamples of the FSR cluster candidates by Bica, Bonatto & Camargo (2008) and Camargo, Bonatto & Bica (2010). They find that about half the investigated candidates are star clusters with a tendency that overdensities with less members are more likely not real clusters. We finally note that the current version of the open cluster data base5 from Dias et al. (2002) contains at the time of writing 141 of the 1022 FSR cluster candidates which have been followed up by the community. Hence, even without a complete and systematic analysis of the entire sample, 15 per cent of the clusters have already been identified as real objects. All of this evidence indicates that at least three quarters of all the confirmed clusters and cluster candidates investigated here are real, or that the contamination of our cluster sample is less than 25 per cent.
Further to the distances, we calculated the extinction and YSO fraction for 775 cluster candidates (43 per cent of the FSR sample, excluding globular clusters). The split of this group into known clusters and new candidates is 378 and 397 objects, respectively, or 56 and 39 per cent of the entire cluster sample. In the following, we will analyse the statistical properties of the entire sample. We will not aim to gauge which of the individual cluster candidates is real or not. This will be done in a forthcoming paper after the ages of the candidates have been determined. However, to aid the reader in evaluating the trustworthiness of individual properties, we add two columns to Table A1 in Appendix A. We list as |$N^{\rm tot}_{2r_{\rm core}}$| the number of stars in the A-sample within two core radii for each cluster. We furthermore sum up all membership probabilities (|$P^i_{\rm cl}$|) of these stars to determine the total estimated number of cluster members |$N^{\rm mem}_{2r_{\rm core}}$| in the same area. As a guide we note that the contrast, i.e. the ratio of cluster members to field stars, is on average twice as high for the known clusters than for the new candidates. This is a clear indication that more pronounced objects are more likely to be real clusters.
3.1 Cluster distribution in the GP
We investigate how the clusters with distances are distributed in the GP and determine completeness limits and selection effects. In Fig. 6, we show the positions of all clusters projected into the GP and the position with respect to the GP as a function of the Galactocentric distance. Note that for all these plots, we assume a distance of 8 kpc of the Sun to the GC.
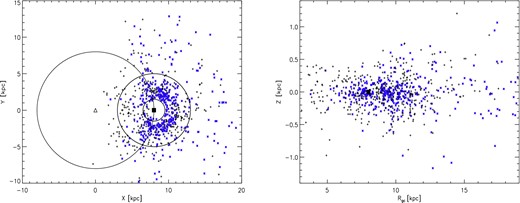
Left: plot of the distribution of FSR clusters in the GP based on the distances determined in this paper. The GC is represented by a triangle. The smaller of the three circles indicates a distance of 1.5 kpc from the Sun, the medium-sized circle indicates a distance of 5 kpc from the Sun and the large circle indicates a distance of 8 kpc from the GC. Right: plot of the height, Z, above and below the GP of our clusters as a function of the Galactocentric distance, Rgc. In both plots, the black crosses represent new cluster candidates, the blue stars represent previously known open clusters and the Sun is represented by a black square.
The density of clusters per unit area in the GP for our sample peaks at about 3 kpc distance from the Sun. We find that averaged over the entire longitude range there are about 15 star clusters per square kiloparsec projected into the GP at a distance of 3 kpc from the Sun in our sample. At 4 kpc distance, the density drops to about half this level. Also towards smaller distances, a similar significant drop in the density of clusters is found. The latter is caused by the well-known selection effect in the FSR list, which includes only clusters of a certain apparent radius (Froebrich et al. 2010). Thus, many nearby clusters were not included in the original FSR sample, or have been excluded by our condition that the cluster core radius should be smaller than 0| $_{.}^{\circ}$|05 (see Section 2.5.1). The drop in numbers at larger distances is in part caused by the same effect – the clusters are too compact to be included and more distant objects are also too faint.
The scaleheight of the clusters with respect to the GP has been calculated for various subsamples of our clusters. We excluded all clusters that have a distance of more than 5 kpc, since we are more likely to detect clusters further away from the mid-plane at large distances due to extinction. The known clusters in our sample have a scaleheight of 235 ± 20 pc while the new cluster candidates have a distribution with a width of 315 ± 30 pc. We also split our sample into potentially younger and older clusters via the fraction of YSOs (old: Yfrac < 1 per cent; young: Yfrac > 1 per cent). Then we find for the young clusters a scaleheight of 190 ± 15 pc, and for the older clusters 300 ± 20 pc. These scaleheights are in between the numbers for clusters older and younger than 1 Gyr in the FSR sample (older: 375 pc; younger: 115 pc; Froebrich et al. 2010). It is also larger than the scaleheight of the dust in the solar neighbourhood (125 pc; Drimmel et al. 2003; Marshall et al. 2006). The potentially younger clusters in our sample show a higher degree of concentration to the GP. In Paper II, we will determine the ages of all clusters and candidates to investigate in more detail the age dependence of the scaleheight.
As can be seen in the original FSR paper (Froebrich et al. 2007) and also amongst the old FSR clusters (Froebrich et al. 2010), the distribution of the clusters along the GP is not homogeneous. In particular, towards the GC the sample is incomplete. This is most likely caused by crowding and low contrast between cluster and field stars. For the older clusters, some of this could be a real effect since old open clusters seem to exist in lower numbers at Galactocentric distances smaller than that of the Sun (Friel 1995).
Here we utilize Kolmogorov–Smirnov (KS) tests (see e.g. Peacock 1983) to investigate if subsamples of the FSR clusters have similar distributions or if they are different. We compare five different samples:
- S1
– clusters with Yfrac < 5 per cent: old clusters;
- S2
– clusters with 5 per cent <Yfrac: young clusters;
- S3
– known open clusters amongst the FSR sample;
- S4
– new FSR cluster candidates;
- S5
– all FSR clusters, except known globulars.
We determine the probability that any two of the samples are randomly drawn from the same parent distribution. We also test the clusters in each sample against a homogeneous distribution (SH). For this we only use clusters that are more than 60° away from the GC, since we know that close to the GC the FSR list is incomplete (Froebrich et al. 2007). We summarize the results in Table 2.
KS-test probabilities that two of our cluster subsamples are drawn from the same parent distribution. S1: older clusters, Yfrac < 5 per cent; S2: young clusters, 5 per cent <Yfrac; S3: known FSR clusters; S4: new cluster candidates; S5: all FSR clusters, except known globular clusters; SH: a homogeneous distribution along the GP – but more than 60° away from the GC.
| S1 | S2 | S3 | S4 | S5 | SH | |
|---|---|---|---|---|---|---|
| S1 | – | 0.25 | 0.02 | 2.53 | 0.43 | 33.8 |
| S2 | 0.25 | – | 39.5 | 4.07 | 9.89 | 17.2 |
| S3 | 0.02 | 39.5 | – | 0.51 | 15.4 | 52.2 |
| S4 | 2.53 | 4.07 | 0.51 | – | 44.6 | 69.6 |
| S5 | 0.43 | 9.89 | 15.4 | 44.6 | – | 76.0 |
| SH | 33.8 | 17.2 | 52.2 | 69.6 | 76.0 | – |
| S1 | S2 | S3 | S4 | S5 | SH | |
|---|---|---|---|---|---|---|
| S1 | – | 0.25 | 0.02 | 2.53 | 0.43 | 33.8 |
| S2 | 0.25 | – | 39.5 | 4.07 | 9.89 | 17.2 |
| S3 | 0.02 | 39.5 | – | 0.51 | 15.4 | 52.2 |
| S4 | 2.53 | 4.07 | 0.51 | – | 44.6 | 69.6 |
| S5 | 0.43 | 9.89 | 15.4 | 44.6 | – | 76.0 |
| SH | 33.8 | 17.2 | 52.2 | 69.6 | 76.0 | – |
KS-test probabilities that two of our cluster subsamples are drawn from the same parent distribution. S1: older clusters, Yfrac < 5 per cent; S2: young clusters, 5 per cent <Yfrac; S3: known FSR clusters; S4: new cluster candidates; S5: all FSR clusters, except known globular clusters; SH: a homogeneous distribution along the GP – but more than 60° away from the GC.
| S1 | S2 | S3 | S4 | S5 | SH | |
|---|---|---|---|---|---|---|
| S1 | – | 0.25 | 0.02 | 2.53 | 0.43 | 33.8 |
| S2 | 0.25 | – | 39.5 | 4.07 | 9.89 | 17.2 |
| S3 | 0.02 | 39.5 | – | 0.51 | 15.4 | 52.2 |
| S4 | 2.53 | 4.07 | 0.51 | – | 44.6 | 69.6 |
| S5 | 0.43 | 9.89 | 15.4 | 44.6 | – | 76.0 |
| SH | 33.8 | 17.2 | 52.2 | 69.6 | 76.0 | – |
| S1 | S2 | S3 | S4 | S5 | SH | |
|---|---|---|---|---|---|---|
| S1 | – | 0.25 | 0.02 | 2.53 | 0.43 | 33.8 |
| S2 | 0.25 | – | 39.5 | 4.07 | 9.89 | 17.2 |
| S3 | 0.02 | 39.5 | – | 0.51 | 15.4 | 52.2 |
| S4 | 2.53 | 4.07 | 0.51 | – | 44.6 | 69.6 |
| S5 | 0.43 | 9.89 | 15.4 | 44.6 | – | 76.0 |
| SH | 33.8 | 17.2 | 52.2 | 69.6 | 76.0 | – |
These tests do reveal that most of the samples have a different distribution along the GP. In particular, the sample of potentially old clusters (S1) seems to be different from most of the other subsamples. Note that probabilities larger than 1 per cent and less than 99 per cent in the KS test are not significant.
3.2 Young clusters
In Paper II, we will determine the ages of all our cluster candidates and investigate the age distribution as well as how the cluster properties such as scaleheight change with age (as discussed above in Section 3.1). So far the only measure of age we have is the fraction of young stars (Yfrac) in each cluster as determined in Section 2.7. In Fig. 7, we show the distribution of the YSO fraction for all clusters.
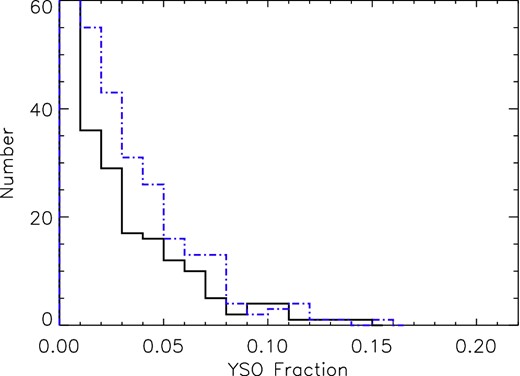
Histogram showing the distribution of Yfrac of our sample. The solid black line represents new cluster candidates and the dot–dashed blue line the known open clusters. The peak in the first bin (Yfrac < 1 per cent) is too high to be shown – 258 new cluster candidates and 165 known open clusters.
There is a steep decrease of the number of clusters with increasing YSO fraction and only a small number of cluster candidates have a high Yfrac. The sample is dominated by clusters with essentially zero YSOs. Only 18 cluster candidates have Yfrac > 10 per cent, and no objects have Yfrac > 20 per cent. The apparent lack of clusters with Yfrac > 20 per cent in our sample means there are potentially no clusters with an age of less than 4 Myr – according to the relation of YSO fraction and age for embedded clusters from Lada & Lada (2003). There are two obvious reasons for this: (i) the FSR list is assembled from NIR 2MASS overdensities, and hence will naturally lack young and embedded objects. (ii) We do not include L-band excess stars in our YSO fraction, and our YSO fraction is a lower limit. Using the L band would require us to include the WISE photometry, and we have seen in Section 2.8 that only about half the 2MASS sources in each cluster can be reliably cross-matched to their WISE counterparts.
The four clusters with the highest YSO fraction are FSR 0488 (Teutsch 168), FSR 1127 (NGC 2311), FSR 1336 (a new cluster candidate) and FSR 1497 (Ruprecht 77).
3.3 Extinction law
As outlined in Section 2.8, we determine a zero-point of (H − K)0 = 0.06 mag by comparing the cluster extinction values determined from the (H − K) and (H − [4.5]) colour excesses and excluding clusters with Yfrac > 0.10. In Fig. 8, we show how the H-band extinction values calculated from the two colour excesses compare to each other. The vast majority of clusters follow the one-to-one line with an rms of 0.18 mag in AH. This even holds for clusters where we were unable to determine a reliable distance.
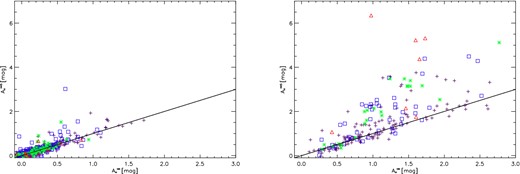
Plot of |$A_{H}^{HK}$| against |$A_{H}^{H45}$|. The red triangles represent clusters with Yfrac > 0.10, the green stars denote clusters with 0.05 < Yfrac < 0.10, the blue squares show clusters with 0.01 < Yfrac < 0.05 and the purple crosses denote clusters with Yfrac < 0.01. The left-hand panel includes all clusters with distances dcal < 5 kpc and the right-hand panel shows all clusters more distant than 5 kpc or where we did not estimate a distance but the extinction.
There are a number of clusters for which the extinction calculated from the (H − [4.5]) excess is significantly higher than that calculated from the (H − K) excess. These differences are most likely due to the fact that only the brightest [4.5] μm sources are matched to 2MASS, and hence the extinction calculation is biased towards intrinsically redder objects. We exclude all clusters more than 3σ above the one-to-one trend line from our subsequent analysis of the dependence of the extinction on the cluster distance.
We estimate how the extinction per unit distance changes for our cluster sample as a function of the Galactic longitude. To establish a reliable value, we apply the following restrictions to our cluster sample: (i) all clusters have to be closer than 5 kpc to the Sun in order to ensure a reliable distance; (ii) the fraction of YSOs should be smaller than 10 per cent for the extinction not to be influenced by disc excess emission stars; (iii) clusters have to be closer than 150 pc to the GP to ensure that the line of sight is mostly in the Galactic mid-plane; (iv) the extinction of the cluster determined from the (H − [4.5]) and (H − K) excesses differs by less than 3σ compared to the one-to-one trend line.
In the left-hand panel of Fig. 9, we show an example of how |$A_H^{HK}$| depends on the distance for our clusters. Only clusters at l = 110° ± 30° are shown. The overplotted solid line is the best linear fit, boxed crosses indicate the clusters used, whilst unboxed crosses mark the clusters excluded by a 3σ clipping. The fit indicates an extinction law of 0.17 mag kpc−1 extinction in the H band. Converted to optical extinction using Mathis (1990), this is AV = 0.9 mag kpc−1.
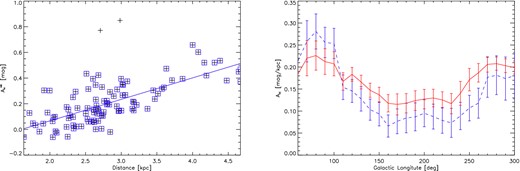
Left: the plot of |$A_{H}^{HK}$| against our calibrated distance values for clusters with l = 110° ± 30°. The crosses represent clusters in this region, and the boxed crosses denote clusters which were not excluded from the fit by our 3σ clipping. Right: the H-band extinction per unit distance as a function of the Galactic longitude. The red solid line represents |$A_{H}^{HK}$| per kpc and the blue dashed line |$A_{H}^{H45}$| per kpc.
We investigate how this extinction law changes as a function of the Galactic longitude in the right-hand panel of Fig. 9. We determine the extinction per unit distance every 10° of the Galactic longitude, but include all clusters that are within 30°. We find that there is a systematic dependence of the extinction per unit distance. The lowest values (AH = 0.1 mag kpc−1) are found near the Galactic anticentre and a steady increase is observed towards the GC where almost AH = 0.3 mag kpc−1 is reached. We only determined the extinction law if there are at least 10 clusters available in the longitude bin. It is important to note that in regions closer than 60° to the GC, very few clusters are available. Fig. 9 also shows that the general behaviour of the extinction values is similar for both |$A_H^{HK}$| and |$A_H^{H45}$|; they are mostly indistinguishable within the uncertainties.
3.4 Potential improvements
One consequence of using 2MASS data to identify stars foreground to the clusters is that the data have a resolution of about 2 arcsec (Skrutskie et al. 2006). Thus, we are unable to resolve close (apparent) binaries and to detect faint cluster members. In other words, crowding in dense cluster centres and generally near the GC or the GP is the limiting factor in our accuracy.
With the availability of deeper homogeneous photometry data sets, such as UKIDSS-GPS (Lucas et al. 2008) and VVV (Minniti et al. 2010), better NIR data will be available for studies of large samples of clusters (e.g. Chené et al. 2012). These deeper and higher resolution data will not only allow the detection of fainter cluster members, but it also allows a more accurate determination of the density of stars foreground to the cluster, since deeper observations generally detect more foreground dwarfs than background giants. Furthermore, these data will also allow us to study more compact and distant clusters, which are currently excluded due to the low spatial resolution.
4 CONCLUSIONS
We present an automatic calibration and optimization method to estimate distances and extinction to star clusters from NIR photometry alone, without the use of isochrone fitting. We employed the star cluster decontamination procedure from Bonatto & Bica (2007a) and Froebrich et al. (2010) to calculate the number of stars foreground to clusters and the BGM (Robin et al. 2003) to estimate uncalibrated model distances.
Our method has been calibrated using two calibration sets of known open clusters. We utilize a homogeneous list of 206 old (>100 Myr) open clusters from the FSR list (Froebrich et al. 2010) as well as all WEBDA entries amongst the FSR clusters. Due to the nature of the entries in the WEBDA data base, the latter calibration set is inhomogeneous, but covers a larger range of ages. We find that the older FSR clusters provide the best calibration sample and we achieve a distance uncertainty of less than 40 per cent after the calibration. Our calibration procedure ensures that all our results are independent of the specific galactic model used.
Using our calibration method, we determined the distances to 771 cluster candidates from the FSR list. Of these, 377 were known open clusters and 394 are new cluster candidates. We also determine the extinction to 775 clusters, 378 known and 397 new candidates. Based on the Q-parameter we also estimate the YSO fraction for each cluster in our sample.
The spatial density of clusters per unit area in the GP for our sample peaks at about 3 kpc distance from the Sun. Thus, our sample is biased towards clusters of this distance and lacks more distant and closer objects. This is caused by the well-known selection effect in the FSR list, which includes only clusters of a similar apparent radius (Froebrich et al. 2010). The scaleheight of the younger clusters (YSO fraction above 1 per cent) is 190 pc, while the remaining (older) clusters show a scaleheight of 300 pc.
We investigated how the extinction per unit distance to the clusters changes as a function of the Galactic longitude. There is a systematic dependence that can at best be described by AH(l) [mag kpc−1] = 0.1 + 0.001 × |l − 180°|/° as long as the clusters are more than 60° from the GC and not embedded in giant molecular clouds. We suggest use of this extinction law, instead of a constant canonical value for any simulations performed with the BGM. In turn this allows us to use our procedure for distance estimates without the need for a calibration sample. In particular, for clusters in the GP but not projected on to giant molecular clouds, the 〈H − [4.5]〉 colour excess can be used as a distance indicator – at least statistically.
The authors would like to thank L. Girardi and B. Debray for their support in accessing the galactic models via a script rather than the web interface. ASMB acknowledges a Science and Technology Facilities Council studentship and a University of Kent scholarship. This publication makes use of data products from the Two Micron All Sky Survey, which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center/California Institute of Technology, funded by the National Aeronautics and Space Administration and the National Science Foundation. This research has also made use of the WEBDA data base, operated at the Institute for Astronomy of the University of Vienna. This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration.
http://www.astro.iag.usp.br/∼wilton/
http://www.astro.iag.usp.br/∼wilton/
REFERENCES
APPENDIX A: FSR CLUSTER PROPERTY TABLE
Summary table of the FSR cluster properties determined with our method (the full table will be published online only). The table lists the FSR ID number, the cluster type (known open cluster or new cluster candidate), the Galactic coordinates and RA and Dec. (J2000), the distance in kiloparsec, the H-band extinction values calculated from the H − K excess (|$A_H^{HK}$|) and from the H − [4.5] excess (|$A_H^{H45}$|), the YSO fraction (Yfrac), the number of stars within two core radii of the cluster centre (|$N^{\rm tot}_{2r_{\rm core}}$|) and the total number of members (calculated as the sum of the membership probabilities of all stars) in the same area (|$N^{\rm mem}_{2r_{\rm core}}$|).
| FSR | Type | l | b | RA | Dec. | d | |$A_{H}^{H45}$| | |$A_{H}^{HK}$| | Yfrac | |$N^{\rm tot}_{2r_{\rm core}}$| | |$N^{\rm mem}_{2r_{\rm core}}$| |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | (°) | (°) | (J2000) | (J2000) | (kpc) | (mag) | (mag) | ||||
| 0001 | New | 0.03 | 03.47 | 17:32:22.2 | −27:03:41 | 4.4 | 0.91 | 1.06 | 0.00 | 1015 | 342 |
| 0002 | New | 0.05 | 03.44 | 17:32:32.4 | −27:03:52 | 4.3 | 0.84 | 1.05 | 0.00 | 365 | 111 |
| 0009 | New | 1.86 | −09.52 | 18:28:29.9 | −31:53:49 | 3.4 | 0.05 | 0.32 | 0.00 | 286 | 73 |
| 0018 | New | 5.34 | 05.41 | 17:37:41.4 | −21:33:27 | 4.1 | 0.41 | 0.53 | 0.00 | 1333 | 337 |
| 0019 | New | 5.52 | 06.08 | 17:35:39.3 | −21:02:50 | 3.8 | 0.27 | 0.44 | 0.00 | 654 | 233 |
| FSR | Type | l | b | RA | Dec. | d | |$A_{H}^{H45}$| | |$A_{H}^{HK}$| | Yfrac | |$N^{\rm tot}_{2r_{\rm core}}$| | |$N^{\rm mem}_{2r_{\rm core}}$| |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | (°) | (°) | (J2000) | (J2000) | (kpc) | (mag) | (mag) | ||||
| 0001 | New | 0.03 | 03.47 | 17:32:22.2 | −27:03:41 | 4.4 | 0.91 | 1.06 | 0.00 | 1015 | 342 |
| 0002 | New | 0.05 | 03.44 | 17:32:32.4 | −27:03:52 | 4.3 | 0.84 | 1.05 | 0.00 | 365 | 111 |
| 0009 | New | 1.86 | −09.52 | 18:28:29.9 | −31:53:49 | 3.4 | 0.05 | 0.32 | 0.00 | 286 | 73 |
| 0018 | New | 5.34 | 05.41 | 17:37:41.4 | −21:33:27 | 4.1 | 0.41 | 0.53 | 0.00 | 1333 | 337 |
| 0019 | New | 5.52 | 06.08 | 17:35:39.3 | −21:02:50 | 3.8 | 0.27 | 0.44 | 0.00 | 654 | 233 |
Summary table of the FSR cluster properties determined with our method (the full table will be published online only). The table lists the FSR ID number, the cluster type (known open cluster or new cluster candidate), the Galactic coordinates and RA and Dec. (J2000), the distance in kiloparsec, the H-band extinction values calculated from the H − K excess (|$A_H^{HK}$|) and from the H − [4.5] excess (|$A_H^{H45}$|), the YSO fraction (Yfrac), the number of stars within two core radii of the cluster centre (|$N^{\rm tot}_{2r_{\rm core}}$|) and the total number of members (calculated as the sum of the membership probabilities of all stars) in the same area (|$N^{\rm mem}_{2r_{\rm core}}$|).
| FSR | Type | l | b | RA | Dec. | d | |$A_{H}^{H45}$| | |$A_{H}^{HK}$| | Yfrac | |$N^{\rm tot}_{2r_{\rm core}}$| | |$N^{\rm mem}_{2r_{\rm core}}$| |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | (°) | (°) | (J2000) | (J2000) | (kpc) | (mag) | (mag) | ||||
| 0001 | New | 0.03 | 03.47 | 17:32:22.2 | −27:03:41 | 4.4 | 0.91 | 1.06 | 0.00 | 1015 | 342 |
| 0002 | New | 0.05 | 03.44 | 17:32:32.4 | −27:03:52 | 4.3 | 0.84 | 1.05 | 0.00 | 365 | 111 |
| 0009 | New | 1.86 | −09.52 | 18:28:29.9 | −31:53:49 | 3.4 | 0.05 | 0.32 | 0.00 | 286 | 73 |
| 0018 | New | 5.34 | 05.41 | 17:37:41.4 | −21:33:27 | 4.1 | 0.41 | 0.53 | 0.00 | 1333 | 337 |
| 0019 | New | 5.52 | 06.08 | 17:35:39.3 | −21:02:50 | 3.8 | 0.27 | 0.44 | 0.00 | 654 | 233 |
| FSR | Type | l | b | RA | Dec. | d | |$A_{H}^{H45}$| | |$A_{H}^{HK}$| | Yfrac | |$N^{\rm tot}_{2r_{\rm core}}$| | |$N^{\rm mem}_{2r_{\rm core}}$| |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | (°) | (°) | (J2000) | (J2000) | (kpc) | (mag) | (mag) | ||||
| 0001 | New | 0.03 | 03.47 | 17:32:22.2 | −27:03:41 | 4.4 | 0.91 | 1.06 | 0.00 | 1015 | 342 |
| 0002 | New | 0.05 | 03.44 | 17:32:32.4 | −27:03:52 | 4.3 | 0.84 | 1.05 | 0.00 | 365 | 111 |
| 0009 | New | 1.86 | −09.52 | 18:28:29.9 | −31:53:49 | 3.4 | 0.05 | 0.32 | 0.00 | 286 | 73 |
| 0018 | New | 5.34 | 05.41 | 17:37:41.4 | −21:33:27 | 4.1 | 0.41 | 0.53 | 0.00 | 1333 | 337 |
| 0019 | New | 5.52 | 06.08 | 17:35:39.3 | −21:02:50 | 3.8 | 0.27 | 0.44 | 0.00 | 654 | 233 |
SUPPORTING INFORMATION
Additional Supporting Information may be found in the online version of this article:
Table A1. Summary table of the FSR cluster properties determined with our method (Supplementary Data).
Please note: Oxford University Press is not responsible for the content or functionality of any supporting materials supplied by the authors. Any queries (other than missing material) should be directed to the corresponding author for the paper.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}