
Abstract
Phishing activity has recently been focused on social networking sites as a more effective way of exploiting not only the technology but also the trust that may exist between members in a social network. In this paper, a novel method for profiling phishing activity from an analysis of phishing emails is proposed. Profiling is useful in determining the activity of an individual or a particular group of phishers. Work in the area of phishing is usually aimed at detection of phishing emails. In this paper, we concentrate on profiling as distinct from detection of phishing emails. We formulate the profiling problem as a multi-label classification problem using the hyperlinks in the phishing emails as features and structural properties of emails along with whois (i.e. DNS) information on hyperlinks as profile classes. Further, we generate profiles based on the classifier predictions. Thus, classes become elements of profiles. We employ a boosting algorithm (AdaBoost) as well as SVM to generate multi-label class predictions on three different datasets created from hyperlink information in phishing emails. These predictions are further utilized to generate complete profiles of these emails. Results show that profiling can be done with quite high accuracy using hyperlink information.
Similar content being viewed by others


1 Introduction
A social network is a group of people who are connected through their communication or use of communication services. The effectiveness of the social network is concerned with the influence of members in the community within a social network (Doyle 2008; Bhattacharyya et al. 2010; Hanneman and Shelton 2011; Rosen et al. 2011).
“Phishing” can be defined as a scam by which a social network is initiated (usually through email but also through social networking technologies) or exploited so that users are duped into surrendering private information that will be used for identity theft. Phishing attacks use both social engineering and technical subterfuge to steal personal identity data and financial account credentials. It is one of the fastest growing scams on the Internet. The exclusive motivation of phishers is financial gain. Phishers employ a variety of different techniques from spoofed links to malware (keyloggers) to DNS Cache Poisoning (Stewart 2003), also known as ‘Pharming’, to lure the unsuspected user into divulging their personal information (Emigh 2005). Spoofing URLs within Phishing emails is a popular deception method. For example, the URL link of http://www.commbank.com.au.stpr.ru/ is seen by the recipient as the target’s URL, http://www.commbank.com.au. Phishers also exploit different vulnerabilities in the browser and other software. These include hiding the actual site addresses in the status bar and redirecting users to spoofed sites.
Usually, a spoofed email is sent to a large group of people from an address that appears to be from the legitimate institution. The email is typically worded to instil a sense of urgency and to elicit an immediate response from the recipient. For example, ‘verify your account details or your account will be closed’. The hoax email also contains a link to an online form that is branded to look exactly like the organization’s website. The form has to be filled in using sensitive information like passwords, user account details and credit card details. Until recently most phishers used the names of financial institutions to deceive people into giving away their account information. They now use the names of other organizations like eBay and Apple.
A report by MarkMonitor, (Brandjacking Index 2009) found that phishing attacks rose 36% in the first quarter of 2009 compared to the same period in 2008 based on a sample of banking brands used in MarkMonitor’s Brandjacking Index report. There was also an increase by 14% in the number of organizations worldwide that were phished, in the first quarter of 2009.
Social networks are increasingly being favoured by phishers as being efficient ways to reach potential victims (Brandjacking Index 2009). Phishing attacks on social networking sites increased by over 240% for the same time last year. The move by phishers to social networking is an attempt to exploit the trust one user has with another in an active social network. A member of a social network or user of social networking software develops a level of trust with other members and has a greater tendency to open up something from a supposedly trusted ‘friend’. This is a significant change in approach that has a stronger social rather than technological focus. Social networking sites have been relatively quick to respond by shutting down phishing attacks on their sites but this does not solve the longer term problems of using the infrastructure of social networking sites for more effective phishing avenues. There is very little work to date specifically on phishing profiling in social networks but there has been some work on profiling the social networks of email spammers (Xu et al. 2009).
There have been many approaches to detect and prevent phishing attacks like anti-phishing toolbars, and scam website blockers (Fette et al. 2007; Wu et al. 2006; Juels et al. 2006). Further machine learning approaches have also been devised for this purpose (Chandrasekaran et al. 2006; Fette et al. 2007). Also another approach to develop an architecture for detecting phishing is proposed in Chau (2005), Jakobsson and Young (2005) and filtering in Cortez et al. (2010). For example, the eBay Toolbar is a browser plugin that eBay offers to its customers, primarily to help them keep track of auction sites. The toolbar has a feature called ‘Account Guard’ that monitors the domain names that users visit and provide warning in the form of a coloured tab on the toolbar. The tab is usually grey but it turns green if the user is on eBay or a PayPal site. It turns red if the user is on a site that is detected as spoofed by eBay. Similarly, spoofguard is an Internet Explorer browser plugin that warns users when webpages have a high probability of being spoofed.
The phishing problem has been and still is very important, and the more recent approaches to use social networking sites are another adaptation of age old techniques with the latest technologies and the social groups themselves being exploited. The detection and warning approach taken to the problem is not enough. The existing literature mainly deals with phishing detection problems. The main problem addressed in the literature is the detection of phishing emails based on some significant features that they possess. In this work a different aspect of phishing is investigated, namely the profiling of phishing emails. Phishers usually follow a variety of techniques, so a profile can be expected to show a conglomeration of different activities. Profiles can be understood as metadata on phishers, in particular, information on activities of a related individual or a group involved in the activity. Profiles can be ascertained to provide information on different phishers involved in the activity. By generating profiles, phishing activities can be better understood as well as monitored. In this paper, we describe an approach based on representing a profile as a set of labels (classes) identified in the phishing emails that align with characteristics useful for profiling. Multi-label classification is used on the links within the emails to predict a set of labels that form a part profile of the phishing activity.
Multi-label classification is a special case of data classification where one or several classes can be assigned to a sample. It is quite natural in text classification that a document (sample) may be from different topics (classes) like “news”, “sport” etc. Multi-label classification methods can be used as applications in different areas, we refer to (Tsoumakas and Katakis 2007; Sebastiani 2002; Yang 1999; Mammadov et al. 2007a, b) and references therein for more information.
The paper is organized as follows. Section 1 provides an introduction to phishing and some background on the literature surrounding the problem. Section 2 focuses on profiling. Sections 3 and 4 describe our formulation of the problem and the data sets that are used and generated to form a basis for this approach. Section 5 presents the classification algorithms used and the evaluation measures. Sections 6 and 7 present the results.
2 Profiling
“Profiling is a data surveillance technique which is little understood and ill-documented, but increasingly used. It involves generating suspects or prospects from within a large population, and inferring a set of characteristics of a particular class of person from past experience” (Clark 1993). In Clark (1993), different data surveillance techniques such as front-end verification and data matching have been surveyed. It has been found that profiling data require different sets of measures and there are different problems that need to be tackled in this area. We take the definition of profiling as in Clark (1993): “Profiling is a technique whereby a set of characteristics of a particular class of person is inferred from past experience, and data-holdings are then searched for individuals for close fit to that set of characteristics”. Furthermore, numerous potential areas for the use of profiling have been identified as well, such as patients who have a likelihood of suffering from certain diseases or disorders, students having potential artistic talents and many others. However, the potential use of profiling has been to identify customers buying patterns and market products accordingly.
Certainly profiling has been in vogue, particularly in areas like “Market Basket Analysis” (Market basket analysis 2011; Petrovic 2007) that profiles customers based on their buying patterns which can further be used by companies to ascertain the nature of competitive markets. Also there have been studies in “Investor Profiling” (Investor Profiles 2011, Interactive Investor Profile Tool 2011), wherein an individual’s investment decisions are taken into account and used to underline the policies and marketing strategies of investment companies. More recently “Offender Profiling” (Alison et al. 2003; FBI method of Profiling 2006) in Forensic Psychology (Webb 2011) is used to identify perpetrator(s) of a crime, based on nature of the offence committed and its mode of operation (Alison et al. 2003; Castle and Hensley 2002). This leads to determination of various aspects of criminal psychology before, during and after the crime is committed.
Further “Customer Profiling” which deals with gathering non-sensitive data about customers (like age, buying patterns and others) is a very important tool in customer relationship management (CRM) activities of companies as can be found in the survey in (Customer Profiling Survey Solution Enabling and Up Selling 2007). Furthermore as is mentioned in the above survey “the more information on customers, the better equipped an organization will be to cater to the needs of their customers”.
In this paper, we follow the same trend set up by these studies. We profile phishing emails based on their structural characteristics and hyperlinks, and use the hyperlink information derived from the “Whois Database” (InterNIC : Whois). Domain names from different countries were present in the hyperlinks, therefore a number of whois databases were queried, including the Asia Pacific Network Information Centre (APNIC) and the Rseaux IP Europens Network Coordination Centre (RIPE NCC) (The APNIC Whois; Ripe Database). Thus, allowing for diversity in the hyperlink information. In our work on understanding phishing activity from a social engineering and social networking point of view we are interested in categorizing the activities of phishing groups and devising techniques for automatically obtaining parts of the group profile.
3 The problem formulation
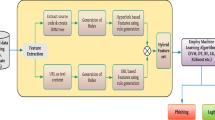
Phishers make contact either through emails or social networking sites. In either case, a hyperlink is used as the conduit for the victims to eventually divulge their sensitive information. Therefore, hyperlinks provide significant information as features. Hence, for our experiments we develop three different datasets from hyperlink information for the generation of profiles. Since our main focus is on phishing via emails, we also incorporate certain structural characteristics found within the phishing emails. We refer to both as structural information, and the hyperlink metadata as the whois information. We consider these characteristics as classes that will correspond to labels in a multi-label classification problem.
The key element of profiling that we focus on in our formulation of the problem is that of inference. In profiling, a particular class (or set of labels) is inferred from examples of their actions and past experience. We propose the use of a multi-label classifier for the inference mechanism in this situation. The multi-label classifier is used to infer the labels in the profiles from some of the features in the email. The problem then becomes one of assessing how well this formulation of the problem performs. We focus on two aspects in this paper: (1) how good the inference is or how well can the classifier predict appropriate labels and (2) in a qualitative sense do the profiles (labels and quantatative importance as indicated by the classifier) make sense?
The process of data classification provides us with the relationships between the hyperlinks and structural phishing email information and their pre-specified categories/classes. Furthermore, we can use the multi-label classifier to assign unknown emails to their categories or classes and therefore to particular attributes in their profiles.
The approach suggested considers:
-
Accessing features from the emails that are simple and effective.
-
The particular characteristics of the emails that can be considered as attributes in profiles.
Our view is that profiles should be able to distinguish between different groups. For example, an email may have the following characteristics, it has a table, an image and so on. Another group may have different subsets of these characteristics. Phishers have different modus operandi or ways of working. In one case, phishers have different ways of handling phishing activity. Some phishers may embed scripts and images in the form which can safely pass detectors and when clicked by the user takes them to a site that is not the original one. In other instances, another group might insert a fake link in the form and when clicked will take the user to a phishing site. Hence the modus operandi is different for different groups.
It has been shown that the modus operandi of a number of Phishing groups correlate to the type of emails used, in terms of both links and certain email characteristics. For example, a plain text Phishing email without any html structure, pictures or tables will have a wording scheme and paragraph structure different to that found in html emails, using tables, images, and fake links. These type of Phishing emails aim to mimic the target organisation directly in order to entice the recipient into being redirected to a form to divulge personal information. On the other hand, a plain text email must engage the recipient on a more personal level in order to get them to follow the fake link so as to divulge their personal information. Therefore, it can be seen that such characteristics are indicative of the type of scheme being used, and thus, can be used directly as classes.
Based on this fact, we would want to identify groups using the different forms of structures embedded inside emails. If we define the feature set as consisting of these characteristics then data clustering would provide different groups having similar profiles. This problem has been considered in Webb et al. (2009).
Preliminary analysis shows that there are many difficult problems in clustering. Different algorithms give different cluster results. In this paper, we follow a different approach. We choose these characteristics as classes and try to predict a set of classes or labels of new emails. The feature set used in this case, is essentially the hyperlink information from emails.
4 Characteristics of the data
Based on the two different types of information, readily obtained, classes were selected for generating profiles. They are: (1) Structural Properties of the emails sent to victims, which present salient characters of the emails; and (2) Whois properties of the hyperlinks, which gives detailed information about a domain hosted on the internet.
The structural properties used as classes are:
-
(a)
textcontent binary value specifying if the email had a text part or was solely an html email. Most phishing emails have multiparts attached to them such as text and html parts. Binary value ‘1’ if the email had a text part and ‘0’ otherwise.
-
(b)
vlinks specification of the number of visible links in the email. The value for this class is ‘1’ if the number of visible links is greater than zero and ‘0’ otherwise. Visible links are mainly used in a phishing email as a disguise for the actual hyperlink.
-
(c)
htmlcontent binary value specifying if the email had a html part or was solely a text email. This would be ‘1’ if the email had html part, ‘0’ otherwise in case of both parts being present in the email, both textcontent and htmlcontent have the value of unity.
-
(d)
script binary value specifying if the email has an embedded script. ‘1’ if email had scripts, ‘0’ otherwise. Preliminary results showed that scripts are an important part of phishing emails as they are usually not picked up by the anti-phishing toolbars. Scripts can perform myriad of activities, such as opening hoax site in another window or storing the username and password. Presence of certain scripts might be a good way to generate a profile.
-
(e)
table determines the number of tables in the email. Value for this class is ‘1’ if the number of tables is greater than zero,‘0’ otherwise. Tables are useful in profile generation as the data in each row of the table can be made to form a hyperlink to some hoax sites. Hence presence of the tables can be used in profile generation.
-
(f)
image/logos determines embedded images and links to images in the email. Value for this class is ‘1’ if the number of images are greater than zero,‘0’ otherwise. Images are a useful tool for profile generation since some emails sent by phishers come in multipart format containing image and text part. Images in particular act as hidden link in transfering the unsuspected user to a phishing site. Hence the presence of images in an email can be used in profiling.
-
(g)
hyperlinks determines the number of hyperlinks in the email. Value for this class is ‘1’ if the number of hyperlinks is greater than zero,‘0’ otherwise. As was discussed earlier, presence of hyperlinks are an important part of an email and phishers take great care in hiding these links.
-
(h)
formtag binary value, ‘1’ if the email had a form embedded, ‘0’ otherwise. Presence of forms in an email would probably open up a data entry window and ask the user to enter their information. On submission, the data would be transferred to the hoax site that is set as the action. Hence this is useful for profiling.
-
(i)
faketags number of faketags in the email. Value for this class is ‘1’ if the number of faketags are greater than zero, ‘0’ otherwise. The faketags are important because they are thrown into the emails to confuse the phishing email detector.
From these structural properties, the email characteristics sent by an individual or a group of phishers can be identified. We use these structural classes for generating the profiles in all the above-mentioned datasets.
Figure 1 shows an email that conforms to example 2 found in Sect. 7. This email contains a number of the above structural properties, including htmlcontent, table, logo and a fake link. It can be seen that the text is formatted inside a html table, has an image of the target’s logo and contains a fake link appearing to belong to the target. Though it cannot be seen in this example, this email contains no scripts or forms, instead the email mimics a typical page found within the target’s web site.

Example email showing structural classes
The example in Fig. 1, clearly shows that the Phishing groups found in this profile, based on the above classes, attempt to make the recipient believe that the email has originated from the target. The aim, therefore, is to lure the recipient into clicking on the fake link so as to be redirected to an online form in order to divulge their personal information. The given example shows that a certain set of structural classes can form a profile describing the actions of one or many groups of Phishers.
Another set of classes are generated from the whois properties of the hyperlinks themselves. Since the hyperlinks are from different countries and were hosted on different domains, information from a number of whois databases was used to generate the classes mentioned here. In recent work (Fette et al. 2007) on detecting phishing emails, the authors had also used ‘whois’ information to select appropriate features for their learning algorithm. In our case, we use whois information as classes. The whois classes were based on the available information retrieved from these databases. Therefore, three different types of whois classes could be determined from the information found on the embedded hyperlinks. The following are the classes generated:
-
(a)
Hacked_Site If a legitimate site was hacked and used to send emails to customers then the value of this would be ‘1’, ‘0’ otherwise.
-
(b)
Hosted_Site If a site was hosted on a server and was used to send emails and receive responses then the value of this would be ’1’, ‘0’ otherwise.
-
(c)
Legitimate_Site_Addition This denotes a hosted site with addition to a legitimate domain. If a site was hosted on a server and its name was just an extension to a legimitate domain address, then this value would be ‘1’, ‘0’ otherwise.
Whois classes are of great significance as they allow for the profiling of phishing activity. Whether an individual hosted their own site or hacked a site or hosted a site very similar to the original with just an addition to it. Particularly, the latter could be hosted in different domains and on different servers. Hence identification of these classes is crucial to profiling phishing emails.
We select a combination of different characteristics as classes to generate the different datasets. The aim being to identify the prominent characteristics that can be used for effective identification of emails. The choice of these classes is based on the rarer characteristics that are prominent in emails but are not so prominent as to be present in most emails. We describe the selection of these classes in Sect. 4.4.
4.1 Information on data
The phishing emails in this paper are 2,048 emails which are obtained from a major Australian Bank. These are emails gathered by their information security group and have been identified/detected as phishing emails. Most emails have been collected over a span of 5 months. Most of the emails are of 1,026 characters in length, have text, and hyperlinks. Some of them contain html structures like script, tables, images and other structures useful in identifying the activities of phishing groups. As previously mentioned, we create different datasets from hyperlink information. However, some emails did not contain hyperlinks thus reducing our final set of documents to 2,038. The datasets generated are listed hereunder.
4.2 Generation of datasets
4.2.1 Hyperlink Based (H)
In this dataset, a complete hyperlink present in an email is taken as a feature. Hyperlinks specify links to a resource usually on the web. In a phishing email, a hyperlink is usually kept hidden from the user. To generate datasets these hyperlinks were extracted from the emails. Hyperlinks can usually be found as values of href attribute of an anchor < a > tag within an email. Emails can have one or more than one feature based on whether one or multiple hyperlinks are present. Hyperlink extraction in phishing emails is particularly more troublesome, because of the presence of spurious tags (similar to the anchor tag) like < acf > to confuse the parsers. Phishers do this to ensure that their hidden links are not picked up by the anti-phishing toolbars and the like. Also junk text deliberately included in the emails makes it more difficult to determine the content.
4.2.2 Hyperlink Suspected Component Based (HS)
In this dataset, the extracted hyperlink is broken down and only the ‘suspected part’ is taken. By ‘suspected part’, we mean that part of the hyperlink which contains information about the directory structure of the link. Usually, a phisher lures an unsuspecting victim to a site which is usually located at a convenient location within a personal directory created by the phisher. So this directory holds all the related files that phishers use to achieve the objective of fetching sensitive information from victims. Hence, a link from any hosted server to this particular directory can be regarded as a suspected link, wherein the suspected part is the link to this directory. It has been observed that in some hyperlinks, although the hosted server remains the same, the directory structure changes as victims from different financial institutions are attacked. Hence, we call this particular dataset Hyperlink Suspected Component Based taking into consideration these facts. An example of suspected part in a hyperlink would be phishing/html/index2.files assuming that the given hyperlink is http://www.domainname.com/phishing/html/index2.file. Our aim in generating this dataset is to identify whether the unseen directory structure of a hyperlink, can provide profile information.
4.2.3 Hyperlink Template Based (HT)
An extracted hyperlink is broken down further into its template format. By ‘template format’, we mean the constituent parts/elements of the hyperlink. For example, given a hyperlink: http://www.domainname.com/phishing/html/index2.files, the template format would be http://www.domainname.com, phishing, html, index2.files. Hence an email in this dataset would usually have multiple features. The generation of this dataset allows for the prediction of an unseen URL to the closest profile template.
The theory behind generating these datasets is that phishers employ different varieties of email links to hide their destination link from the victim. Essentially, these datasets are designed to pick up these different formats. Another point worth mentioning here is that we would also be interested in observing how these three profiles generated correspond to one other.
4.3 Choice of hyperlinks as features
A hyperlink in an html page signifies a link to a resource on the web that can be loaded in the browser when some event occurs. For example, mouse click on the hyperlink. Phishers usually utilize this technique to transfer an unsuspecting user to a hoax site. Usually emails are the modus operandi of phishers trying to contact their potential victims. Emails would be less useful for phishing activity if hyperlinks could not be embedded in them.
Certainly, a lot of care is taken to disguise an embedded link. For example some emails contain a link embedded in a picture that the user sees on opening the email. Clicking on this picture would send the user to a phishing site. A further technique found in emails allows for the embedded link to be invisible to the user. Hence, it does not appear in the status bar. Since this is such an important feature to a phisher, hyperlinks are, therefore, used for generating profiles.
4.4 Selection of classes
When generating profiles we need to use those characteristics that would best distinguish between the different phishing groups. For this reason, we consider the occurrence frequencies of the characteristics considered above. Out of all the structural characteristics, we have the following frequencies listed in Table 1.
It can be seen from Table 1 that some classes have very high frequencies and hence may not be good discriminators between the emails. Therefore, as mentioned below, we use these classes to further generate different sets of classes for classification purposes.
4.5 Shorter featured and multi-label datasets
We are left with multiple classes, thus allowing us to treat the problem of profile generation as a multi-label classification problem. This problem is based on the classes in Table 2 as labels which will constitute elements of the profile.
For classification purposes, the performance of the data classification methods depends on how much information is provided by a feature set. In general, the greater the number of informative features present, the more accurate classification can be performed. Datasets considered in this paper have extremely sparse feature set representations given by Hyperlink Based, Hyperlink Suspected Component Based and Hyperlink Template Based features defined above. They can be classified as Shorter Featured and Multi-Label (SFML) datasets introduced recently (see Mammadov et al. (2007a, b) and references therein).
N denotes the number of examples, N F the number of features, N nzF the total “non-zero” features (i.e., actual feature values provided) in the whole dataset.
In Mammadov et al. (2007b), informativeness of dataset is described by two characteristics: Informativeness of feature set and Multilabel characteristics.
-
1.
Informativeness of a feature set is described by two numbers:
-
GI = N F /N The ratio of the size of the feature set to the number of data points describes the general informativeness of the feature set in terms of the size of data. Higher values for this ratio can be expected to allow better separability of classes in the feature space.
-
AI = N nzF /N The average number of “non-zero" features (that is, features actually used) per example is another characteristic describing the informativeness of the feature set. Lesser values for this characteristic are expected to restrict the possibility of better classification.
-
-
2.
Multilabelness characterized by number N C , is depicted by the average number of classes per example. Larger multilabelness, that is, a larger value of N C is a factor that complicates the classification process.
SFML datasets are defined to have lesser values for GI and AI and higher values for N C . Such datasets can be found from different areas. Examples are: datasets related to the Adverse Drug Reaction problems in Medicine and some text classification problems involving SMS messaging [see Mammadov et al. (2007b) and references therein].
Datasets considered in this paper provide another set of examples for SFML datasets. They have very small values for GI and AI, and at the same time, very high multilabelness values of N C . Table 3 summarizes the characteristics of these datasets. We can observe that in data H + C12 the average number of features actually presented per example is 1.28. Meanwhile, the average number of classes per example is very large 5.589, this indicates quite high multilabelness of data H + C12.
5 Classification algorithms and evaluation measures Used
5.1 Algorithms
In the experiments, we use two different algorithms. BoosTexter, proposed in Schapire and Singer (2000), is a well-known classification algorithm developed for multi-label classification problems. In Wu (2008), it is listed as one of the top 10 algorithms in Data Mining. It is based on the boosting concept in machine learning (Freund and Schapire 1999). Boosting increases classifier accuracy by combining rules generated at each round by a weak learning algorithm. BoosTexter uses two algorithms to solve multi-label classification problems, namely AdaBoost.MH and AdaBoost.MR (Schapire and Singer 2000). It generates more accurate classification rules after sequentially calling the weak learner in a series of rounds. In our experiments, we run BoosTexter for 300 rounds. We refer to (Schapire and Singer 2000; Wu 2008; Freund and Schapire 1999) for more details. Another classification algorithm that we use to generate profiles is SVM_light - an implementation version of Support Vector Machines (Joachims 2002).
5.2 Evaluation measures
The evaluation measures such as accuracy, prediction, recall are commonly used measures in the literature [see e.g.,Tsoumakas and Katakis (2007);Tang et al. (2009)] and the references therein). In this paper, we use the measures proposed in Schapire and Singer (2000), called One-Error, Coverage and Average Precision. They are specially designed for multi-label classification problems and have been using in the literature by different authors over the past many years. On the other hand, these rank-related measures are more suitable for this research, as the classes on the top of the ranking get more emphasize in the profiles generated. We use the modified versions of these measures given below.
Let \({{\mathcal{X}}}\) be the set of all documents. Given document \({x \in {\mathcal{X}},}\) classification algorithm generates a prediction vector \({{\mathcal{H}}(x) = ({\mathcal{H}}_1(x), \ldots, \mathcal{H}_c(x))}\) where c is the number of classes. Higher values of \(\mathcal{H}_i(x), i = 1 \cdots c,\) indicate the classes that the document x is more likely to belong to. In the following, the notation |S| represents the cardinality of the set S. Moreover, \((\mathcal{Y}_1(x), \ldots, \mathcal{Y}_c(x))\) denotes the vector of actual classes related to x, where \(\mathcal{Y}_i(x) = 0\) or \(\mathcal{Y}_i(x) = 1.\)
-
1.
One-error:
This measure evaluates errors in the prediction of classes related to the “maximal” element in the prediction vector \(\mathcal{H}(x) = (\mathcal{H}_1(x), \ldots, \mathcal{H}_c(x)).\) In cases, where there are more than one class, having the same maximal weight in the prediction vector, this measure needs to be defined. Consider \(\mathcal{H}^*(x) = \{ i \in \{1, \ldots, c \}: \mathcal{H}_i(x) = max \{ \mathcal{H}_1(x) \cdots \mathcal{H}_c(x) \} , \) and \(\mathcal{Y}^*(x) = \{ i \in 1, \ldots, c \}: i \in \mathcal{H}^*(x)\) and \(\mathcal{Y}_i(x)=1\}.\) Then one-error is defined as:
$$ E_{\text{one-error}}=\frac{1}{|{\mathcal{X}}|} \sum_{x \in {\mathcal{X}}} \left( 1- \frac{|{\mathcal{Y}}^*(x)|}{|{\mathcal{H}}^*(x)|}\right) $$(1) -
2.
Coverage:
This measure evaluates the performance of a classifier for all classes that have been observed. For each \(x \in \mathcal{X},\) we denote by \(\Upgamma(x)\) the set of all ordered classes \(\tau = \{ i_1, \cdots, i_c \} \subset \{1, \ldots, c\}\) satisfying \(\mathcal{H}_{i1}(x) \geq \ldots \geq \mathcal{H}_{ic}(x).\) Given an order \(\tau \in \Upgamma(x)\) the rank and the error is defined as:
$$ rank_\tau(x)=max_{i \in \{ 1,\ldots,c \}} \{i:{\mathcal{Y}}_i(x) = 1 \}; $$(2)$$ {\text{error}}_\tau(x)=\frac{rank_\tau(x)}{||{\mathcal{Y}}(x)||} -1. $$(3)where \(||\mathcal{Y}(x)|| = \sum_i \mathcal{Y}_i(x)\) is the number of actual classes. Obviously the terms rank τ and error τ depend on the order τ. One way to avoid the dependence on ordering is to take the middle value of the maximal and minimal ranks. In this work, this value is used for the definition of the rank defined by:
$$ {\text{rank}}(x) =\frac{1}{2}({\text{rank}}_{\text{max}}(x) + {\text{rank}}_{\text{min}}(x)); $$(4)where
$$ \begin{aligned} {\text{rank}}_{\text{max}}(x)&={\text{max}}_{\tau \in \Upgamma(x)} {\text{rank}}_\tau(x)\\ {\text{rank}}_{\text{min}}(x)&={\text{min}}_{\tau \in \Upgamma(x)} {\text{rank}}_\tau(x) \end{aligned} $$The numbers rankmax(x) and rankmin(x) are associated with the worst and best ordering respectively. To define coverage the following formula will be used:
$$ E_{\text{cov}}=\frac{1}{|{\mathcal{X}}|} \sum_{x \in {\mathcal{X}}} \left ( \frac{rank(x)}{||{\mathcal{Y}}(x)||} - 1 \right) $$(5)It must be noted that E cov = 0 if a classifier makes predictions such that for all \({x \in {\mathcal{X}},}\) the actual classes are placed on the top of the ordering list of weights \({{\mathcal{H}}_i(x).}\)
-
3.
Average precision:
Denote \(Y(x) = \{l \in \{1, \ldots, c\}: \mathcal{Y}_l(x) = 1 \}.\) Given order \(\tau = \{\tau_1, \ldots, \tau_c\}\in \mathcal{T} (x),\) we define the rank for each class \(l \in Y(x)\) as rankτ (x; l) = k, where the number k satisfies τ k = l. Then Precision is defined as:
$$ P_{\tau}(x)=\frac{1}{|Y(x)|} \times \sum_{l \in Y(x)} \frac{|\{k \in Y(x): {\text{rank}}_\tau (x; k) \le {\text{rank}}_\tau (x; l)\}|} {{\text{rank}}_\tau (x; l)}. $$This measure has the following meaning. For instance, if all observed classes Y(x) have occurred on the top of ordering τ then P τ(x) = 1. Clearly the number P τ(x) depends on the order τ. We define
$$ P_{\text{best}}(x) = \max_{\tau \in {\mathcal{T}}(x)} P_{\tau}(x)\quad\hbox{and}\quad P_{\text{worst}}(x) = \min_{\tau \in {\mathcal{T}} (x)} P_{\tau}(x) $$which are related to the ‘best’ and ‘worst’ ordering. Therefore, it is meaningful to define the Precision as the midpoint of these two versions:
$$ P(x) = (P_{\text{best}}(x) + P_{\text{worst}}(x))/2. $$Average Precision over all records \({{\mathcal{X}}}\) will be defined as:
$$ P_{\text{av}} = \frac{1}{|{\mathcal{X}}|}\sum_{x \in {\mathcal{X}}} P(x). $$(6)For all experiments conducted in this work, the above-mentioned measures are used as the performance measures for the determination of classifier accuracy. From the above, it can be seen that Average Precision is more suitable for multi-label evaluation problems.
6 Classification results
In generating predictions from BoosTexter described in Sect. 5, we use a bag-of-words approach in which hyperlinks from emails are the features and structural and whois information are the classes. Hence, we would have an input feature vector and an input class vector being provided to the algorithm to generate a prediction vector. To evaluate the classifier’s accuracy we perform four-fold cross-validation on all the datasets mentioned in Sect. 4.2. Further we evaluate classifier performance using the performance measures described in Sect. 5 .
The number of documents is also presented in Tables 4, 5, 6, 7, 8. When considering feature sets Hyperlink Based (H) and Hyperlink Template Based (HT), we observe that all documents have at least one such feature, therefore the number of documents related to these features are the same for all class combinations. However, some documents do not have Hyperlink Suspected Component Based (HS) features, such documents are consequently removed. The same happens when considering different class combinations. In generating datasets for different class combinations all the documents with no classes assigned are removed
6.1 Results for 12 classes
BoosTexter achieves quite high accuracy on these datasets. This means that the profiles, described in terms of the structural characteristics of emails, can be accurately predicted by the present hyperlinks.
Results of One-Error, Coverage and Average Precision from Boostexter are presented in Table 4. The results are averaged over four folds. Further results from SVM using the linear kernel have been presented.
The results presented in Tables 4 and 5 show that BoosTexter significantly outperforms SVM. This is consistent with the results obtained for several SFML datasets [see Mammadov et al. (2007b) and references therein].
Hence for these types of datasets boosting algorithms can be a suitable choice for generating profiles. The above results also show that, Average Precision is higher on Hyperlink Template Based dataset which could be expected, since breaking a hyperlink into separate parts will generate more features for the algorithm to learn. The important fact is that the accuracy on the test set also increases. Furthermore, the number of examples in the Hyperlink Suspected Component Based dataset is less than the others, since not all hyperlinks do have a link to the directory structure.
6.2 Results for 9, 6 and 3 classes
According to the results of the previous section, we will only use the algorithm BoosTexter for further experiments. In Tables 6, 7, and 8, we present the results obtained for 9, 6 and 3 classes respectively. These classes are related to the class sets C9, C6 and C3 provided in Table 2. When considering nine classes, obtained by removing the first three most frequently occurring classes (vlinks, htmlcontent and link), some records are left with no classes assigned. The same happens when considering 6 and 3 classes. Consequently, we removed all such records having no classes assigned. The number of records remaining is provided in the corresponding tables.
By analysing the results in Tables 6, 7, and 8, we observe that Hyperlink Suspected Component Based (HS) achieves higher accuracy in classification. However to extract these features requires an extra work for data generation and moreover not all emails contain such features. On the other hand, Hyperlink Based (H) and Hyperlink Template Based (HT) features are much easier to extract and they provide almost the same accuracy as HS. In view to this fact Hyperlink Based (H) is more preferable, as it does not need to extract additional features by breaking a hyperlink down into its constituent elements that may complicate the classification process. We should also note that this is a plausible justification and further work may include a more intensive analysis of the three techniques.
7 Profile generation results
To generate profiles, the results generated by the classifier are used. BoosTexter generates predictions in which the most related class has the highest weight and the least related class has the least weight. Following the notation mentioned in Sect. 5, a prediction vector generated by the classification algorithm is given by \(\mathcal{H}(x) = (\mathcal{H}_1(x), \ldots, \mathcal{H}_c(x))\) where c is the number of classes for each document \({x \in {\mathcal{X}}; }\) \({{\mathcal{X}}}\) being the set of all documents. In the prediction vector, the condition \(\mathcal{H}_i(x) > 0\) will mean that the example belongs to class i. Further, \(\mathcal{H}_j(x) > \mathcal{H}_i(x)> 0 \) will mean that the example is more related to class j than to class i. Further, classes that do not correspond to this particular example have negative weights.
Our method of profile generation from predictions constitute the following steps:
-
Step 1: Arrange the prediction vector \({{\mathcal{H}}(x)}\) in a descending order.
-
Step 2: Generate a complete profile involving the classes related to the order in Step 1.
Below we present some results from the profile generation experiments. We present three examples on Hyperlink Based(H + C9, H + C6 and H + C3) datasets. Similar profiles can be generated from Hyperlink Suspected Component Based and Hyperlink Template Based datasets. Weights for different classes as generated by the classifier are also presented. Moreover, we also provide our interpretations of the profiles.
Example 1
Profile generated from Whois classes based on the Hyperlink Based dataset (H + C3).
-
Feature: http://www.netbank.commbank.com.au.lliiilllli.net/netbank/bankmain/
-
Prediction: Hosted Site: 0.047; Legitimate Site Addition: 0.033; Hacked Site: −0.047,
-
Profile generated: This group prefers using hosted sites with legitimate target names added to the URL. They do not however use hacked sites.
Example 2
Profile generated from a number of Structural classes based on the Hyperlink Based dataset (H + C6).
-
Feature: http://www.ravak.co.uk/index.html
-
Prediction: table: 0.023; image: 0.024; faketags: 0.022; text content: 0.023; script: −0.028; form: −0.036;
-
Profile generated: This group prefers using tables, images, faketags and text content in their emails. However, they do not use any scripts or forms.
Example 3
Profile generated from both Whois and Structural classes based on the Hyperlink Based datasets (H + C9).
-
Feature: http://www.commonwealth-security.com
-
Prediction: Hosted_Site: 0.026; Legitimate_Site_Addition: −0.026; table: 0.024; image: 0.024; faketags: −0.016; Hacked Site: −0.026; text content: 0.026; script: −0.018; form: −0.035;
-
Profile generated: This group prefers using hosted sites without adding legitimate target names to the URL and prefer not to use hacked sites. Furthermore, they include tables, images and text content in their emails and prefer not to use fake tags, scripts or forms.
Example 1
Uses Whois classes derived from domain hosting information about the given hyperlink. Emails found in this profile contain URLs that are not from hacked sites, but instead are hosted with usually non descript names and have the target name added as a subdomain. These URLs are created to fool an unsuspected user into thinking that the email originates from the legitimate target domain. The hosted site is on a different domain to that of the target, but the target name is superimposed on the legitimate site http://www3.netbank.commbank.com.au, as is evident from ‘Hosted_Site’ and ‘Legitimate_Site_Addition’ classes. In terms of the weights generated by the classifier, ‘Hosted_Site’ and ‘Legitimate_Site_Addition’ have similar weights. Adding further evidence to the fact that the phishing site is a hosted site designed to lure the user.
It can be seen that the directory structure within the hosted server is netbank/bankmain/
This directory structure further attempts to convince the unsuspected user into thinking that it is the target site.
Example 2
The classes supplied in this example are structural classes. Emails found in this profile use both tables to format the emails into the web page structures used by the target and links to images taken from the target’s website. Furthermore, the text content is used to mimic the text found on the websites of the target. A class uniquely associated with the emails of this profile is in the use of fake tags. Fake tags are used to complicate the parsing process of a phishing filter, thus impeding its ability to correctly classify the emails as phishing. Furthermore, the mode of operation in this profile does not include using scripts or embedded forms within the email. Instead, the aim is to lure the unsuspected victim to a fake site via the hyperlink.
Example 3
The classes supplied in this example are both structural and whois classes. This example shows that all URLs from emails in this profile use hosted sites but do not add legitimate target names to the URL. As seen in this example http://www.commonwealth-security.com, this URL has a domain name made to look like the target name, hence fooling the unsuspected user. Emails found in this profile will contain tables holding a structure of both images and text that mimic the look and feel of the target’s web interfaces. These are links to pictures that have been taken from the target’s websites and the text content is worded to mimic the semantical language used by the target.
Forms and scripts are not used for retrieving information from the user, instead the phisher(s) rely on transferring the unsuspected user to the hoax site to extract information.
8 Conclusions
In this paper, we have presented a novel method for obtaining profiles from phishing emails using hyperlink information as features, and structural and whois information as classes. We have transformed the problem of profiling into a multi-label classification problem in which profiles are generated based on the predictions of the classifier. We have used well-known classification algorithms (BoosTexter and SVM) for our experiments. We create three different datasets from the hyperlink information in emails and use four-fold cross-validation to generate our predictions. Furthermore, we consider subsets of feature classes from either structural or Whois or both class sets in order to give a more comprehensive profile breakdown.
The results from BoosTexter for the 12 classes provided very high classification accuracy, therefore the 3, 6 and 9 subset combination experiments were carried out using only this classifier. We then provided prediction weights generated by the classifier that show the relative importance of the classes used in all profiles generated. In future, we would enhance this technique further by focussing on the more prominent features and develop more representative classes for profiling. Also we would like to experiment further with different classifiers and compare the profiles generated in the process. Finally, we aim to achieve a valid criterion for measuring the importance of the classes used in the profiling process.
References
Alison L, Smith M, Eastman O, Rainbow L (2003) Toulmin’s philosophy of argument and its relevance to offender profiling. Psychol Crime Law 9(2):173–183
Bhattacharyya P, Garg A, Wu SF (2010) Analysis of user keyword similarity in online social networks. Social Netw Anal Min. doi:10.1007/s13278-010-0006-4
Brandjacking index (2009) Markmonitor.com, Spring 2009. http://www.markmonitor.com/download/bji/BrandjackingIndex-Spring2009.pdf
Castle T, Hensley C (2002) Serial killers with military experience: applying learning theory to serial murder. International J Offender Ther Comp Criminol 46:453–465
Chandrasekaran M, Karayanan K, Upadhyaya S (2006) Towards phishing e-mail detection based on their structural properties, In: Proceedings of the New York State Cyber Security Conference
Chau D (2005) Prototyping a lightweight trust architecture to fight phishing, MIT Computer Science and Artificial Intelligence Laboratory, Tech. Rep., final Report. http://groups.csail.mit.edu/cis/crypto/projects/antiphishing/
Clark R (1993) Profiling: a hidden challenge to the regulation of data surveillance. J Inf Sci 4(2)
Cortez P, Correia A, Sousa P, Rocha M, Rio M, Perner P (2010) Spam Email Filtering Using Network-Level Properties. In: Proceedings, Advances in Data Mining Applications and Theoretical Aspects. 10th Industrial Conference, ICDM 2010. Berlin, Germany
Customer profiling survey solution enabling cross and up selling (2007) Confirmit. http://www.confirmit.com/home.aspx
Doyle S (2008) Social network analysis in the telco sector marketing applications. J Database Mark Cust Strategy Manag 15:130–134
Emigh A (2005) Online identity theft: Phishing technilogy, chokepoints and countermeasures, Radix Labs, Tech. Rep., retrieved from Anti-Phishing Working Group. http://www.antiphishing.org/resources.html
FBI method of profiling (2006) Wikipedia, January 2006, retrieved June 10, 2011. http://en.wikipedia.org/wiki/FBI_method_of_profiling
Fette I, Sadeh N, Tomasic A (2007) Learning to detect phishing emails. In: WWW ’07: Proceedings of the 16th international conference on the World Wide Web. New York, NY, USA. ACM Press, New York, pp 649–656
Freund Y, Schapire R (1999) A short introduction to boosting, J Jpn Soc Artif Intell 14(5):771–780
Hanneman RA, Shelton CR (2011) Applying modality and equivalence concepts to pattern finding in social process-produced data. Soc Netw Anal Min 1(1):59–72
Interactive investor profile tool (2011) Southside Bank: Trust & Investment Services Group, retrieved June 10, 2011. http://www.southsidetrust.com/tool.html
InterNIC : Whois search InterNIC—Public information Regarding Internel Domain Name Registration Services. http://www.internic.net/whois.html
Investor profiles (2011) The National Mutual Life Association of Australasia Limited, retrieved June 10, 2011. http://www.axafreedom.com.au/freedom/freedom.nsf/content/InvestorProfiles
Jakobsson M, Young A (2005) Distributed phishing attacks, Cryptology ePrint Archive, Report 2005/091. http://eprint.iacr.org/
Joachims TJ (2002) Learning to classify text using support vector machines: methods, theory and algorithms. Kluwer Academic Publishers, Dordrecht
Juels A, Jakobsson M, Jagatic TN (2006) Cache cookies for browser authentication (extended abstract), In: SP ’06: Proceedings of the 2006 IEEE Symposium on Security and Privacy (S&P’06). minus 0.4em Washington, DC, USA. IEEE Computer Society, NW, pp 301–305
Mammadov M, Rubinov A, Yearwood J (2007a) The study of drug-reaction relationships using global optimization techniques. Optim Methods Softw 22(1):99–126
Mammadov M, Yearwood J, Banarjee A (2007b) Classification on shorter featured and multi-label datasets. In: Proceedings of the 7th International Conference on Optimization: Techniques and Applications (ICOTA07), December 12–15, Kobe, Japan
Market basket analysis (2011) Information drivers, retrieved June 10, 2011. http://www.information-drivers.com/market_basket_analysis.php
Petrovic D (2007) Analysis of consumer behaviour online, Analogik.com, Tech. Rep., retrieved June 10, 2011. http://analogik.com/articles/227/analysis-of-consumer-behaviour-online
Ripe database RIPE Network Coordination Centre. http://www.ripe.net/index.html
Rosen D, Barnett GA, Kim JH (2011) Social networks and online environments: when science and practice co-evolve. Soc Netw Anal Min 1(1):27–42
Schapire R, Singer Y (2000) BoosTexter: a boosting-based system for text categorization. Mach Learn 39(2/3):135–168
Sebastiani F (2002) Machine learning in automated text categorization. IACM Comput Surv (CSUR) 34(1). doi:10.1145/505282.505283
Stewart J (2003) DNS cache poisoning—the next generation, Secure Works, Tech. Rep. http://www.secureworks.com/research/articles
Tang L, Rajan S, Narayanan VK (2009) Large scale multi-label classification via metalabeler. In: Proceedings of the 18th international conference on World Wide Web, ACM Press, New York, pp 211–220
The APNIC whois Asia Pacific Network Information Center. http://wq.apnic.net/apnic-bin/whois.pl
Tsoumakas G, Katakis I (2007) Multi-label classification: an overview. Int J Data Warehous Min 3(3):1–13
Webb D (2011) A free and comprehensive guide to the world of forensic psychology, All About Forensic Psychology, retrieved June, 2011. http://student-guide-to-forensic-psychology.blogspot.com/
Webb D, Yearwood J, Vamplew P, Liping M, Ofoghi B, Kelarev A (2009) Applying clustering and ensemble clustering approaches to phishing profiling. In: Proceedings of AusDM 2009, The Australasian Data Mining Conference 2009. CRPIT
Wu X, et al (2008) Top 10 algorithms in data mining. Knowl Inf Sys 14:1–37
Wu M, Miller R, Little G (2006) Preventing phishing attacks by revealing user intentions. In: Symposium on Usable Privacy and Security (SOUPS)
Xu KS, Kliger MM, Yilun C, Woolf PJ, Hero A (2009) Revealing social networks of spammers through spectral clustering. In: Proceedings of the IEEE International Conference on Communications. Dresden, Germany. doi:10.1109/ICC.2009.5199418
Yang Y (1999) A re-examination of text categorization methods. In: Proceedings of SIGIR-99, 22nd ACM International Conference on Research and Development in Information Retrieval
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yearwood, J., Mammadov, M. & Webb, D. Profiling phishing activity based on hyperlinks extracted from phishing emails. Soc. Netw. Anal. Min. 2, 5–16 (2012). https://doi.org/10.1007/s13278-011-0031-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13278-011-0031-y