
Abstract
The algorithm for and results of a newly developed multivariate non-parametric model, the Euclidean distance model (EDM), for the hourly disaggregation of daily climate data are presented here. The EDM is a resampling method based on the assumption that the day to be disaggregated has already occurred once in the past. The Euclidean distance (ED) serves as a measure of similarity to select the most similar day from historical records. EDM is designed to disaggregate daily means/sums of several climate elements at once, here temperature (T), precipitation (P), sunshine duration (SD), relative humidity (rH), and wind speed (WS), while conserving physical consistency over all disaggregated elements. Since weather conditions and hence the diurnal cycles of climate elements depend on the weather pattern, a selection approach including objective weather patterns (OWP) was developed. The OWP serve as an additional criterion to filter the most similar day. For a case study, EDM was applied to the daily climate data of the stations Dresden and Fichtelberg (Saxony, Germany). The EDM results agree well with the observed data, maintaining their statistics. Hourly results fit better for climate elements with homogenous diurnal cycles, e.g., T with very high correlations of up to 0.99. In contrast, the hourly results of the SD and the WS provide correlations up to 0.79. EDM tends to overestimate heavy precipitation rates, e.g., by up to 15% for Dresden and 26% for Fichtelberg, potentially due to, e.g., the smaller data pool for such events, and the equal-weighted impact of P in the ED calculation. The OWPs lead to somewhat improved results for all climate elements in terms of similar climate conditions of the basic stations. Finally, the performance of EDM is compared with the disaggregation tool MELODIST (Förster et al. 2015). Both tools deliver comparable and well corresponding results. All analyses of the generated hourly data show that EDM is a very robust and flexible model that can be applied to any climate station. Since EDM can disaggregate daily data of climate projections, future research should address whether the model is capable to respect and (re)produce future climate trends. Further, possible improvements by including the flow direction and future OWPs should be investigated, also with regard to reduce the overestimation of heavy rainfall rates.
Similar content being viewed by others


1 Introduction
Climate data with high temporal resolution are needed in a multitude of hydrological models (e.g., WaSim-ETH, MIKE FLOOD) or ecological models (e.g., SWAT-CN, GASFLUX) and for climate research and analysis. Additionally, the investigation of climate-related extremes and the changes in climate statistics are an important and relevant topic of research.
A common problem is that often only daily observations are available with sufficient spatial resolutions and sufficiently long time series since hourly measurements are more difficult, expensive, and high-maintenance. Hence, hourly time series are often not available and do not have appropriate lengths or contain gaps due to failures of the measuring equipment. To adapt to this lack of data, there are several methods to generate, complete, or extend the hourly time series of different climate elements. However, most of them are designed for the disaggregation of only one or two climate elements focusing on the disaggregation of precipitation as in e.g., Glasbey et al. (1995), Güntner et al. (2001), Lisniak et al. (2013), Lee and Jeong (2014), and Lu et al. (2015). Only a few models have been developed for the disaggregation of more than one climate element, such as in Debele et al. (2007), Mezghani and Hingray (2009), or Kim et al. (2016). These disaggregate daily temperature data among others. Temperature is the second most disaggregated climate element.
All disaggregation approaches are based either on parametric or non-parametric methods. For example, the method of Lisniak et al. (2013) is a parametric one for the temporal disaggregation of daily data based on multiplicative random cascades (MRC) as described by Olsson (1998) and Güntner et al. (2001). The method of Kim et al. (2016) is also a parametric one for statistical downscaling based on generalized linear modeling (GLM), as described in McCullagh and Nelder (1989). Beck and Bárdossy (2013) developed an indirect downscaling method based on a fuzzy logical classification and Bárdossy (1998) used simulated annealing for the simulation of precipitation time series. Examples of no-nparametric approaches include the methods of Mezghani and Hingray (2009), Sharif et al. (2013), Lee and Jeong (2014), and Lu et al. (2015). These three stochastic approaches are based on K-nearest neighbor resampling (KNR).
The Euclidean distance model (EDM) presented here is also based on a non-parametric resampling method. It is able to disaggregate daily mean/sum values of temperature, precipitation, sunshine duration, relative humidity, and wind speed, filling the need for a model that generates hourly data for a combination of climate elements and with a physical consistency over all disaggregated climate elements.
The EDM differs from the KNR mainly in the kind of a priori information considered in the classification of the object of interest into preexisting classes. The KNR is based on (i) a suitable distance metrics (e.g., Euclidean distance, Manhattan distance, Mahalanobis distance) and on (ii) the consideration of the total number of objects that have been divided into classes. Hence, besides the distance measure in the feature space, also, the a priori probability with which an object can be expected in one of the preassigned classes is considered. This is quite similar to a maximum likelihood approach. However, for classes with only a small number of objects, the signal-to-noise ratio and with it the goodness of classification can decrease. This may happen, especially, when the underlying data are not equally distributed or the sample size of the data is too small. Similar to KNR, also, the EDM considers a priori information in the disaggregation process, but here in a kind of memorization of historically similar events, known as the method of analogous cases.
The EDM is based on the assumption that the day to be disaggregated (hereafter called disaggregation day) has occurred at least once in the past with more or less the same weather conditions. In the EDM approach, the minimum distance serves as the pointer to the most similar day in the historical data set. As disaggregation is an under-determined task, observations, physical model assumptions, and arguments of plausibility are required for its solution. The choice of the distance metrics is arbitrary to some degree. Due to a lack of sufficient a priori information required for the determination of more sophisticated metrics (e.g., employing covariance matrices), the Euclidean distance is used as a sufficiently simple and robust distance measure for the present purposes. The consideration of the method of analogous cases has the important advantage of reducing the degrees of freedom in the disaggregation procedure by including direct observations.
Since the EDM works without any calibration or preassigned classifications, it disaggregates each single day independently and flexible, and potential changes in the classifications and climate variations are no limitation for the EDM. Further, it is a location-independent model that can be applied to any other region or station. Only observed hourly and corresponding daily data are required. And also, daily values outside the observed range of cases can therefore be disaggregated since only a diurnal cycle of the past is transferred and due to applied quotients, the daily values are conserved. But if there are not yet observed characteristics of diurnal cycles, e.g., caused by climate change, the EDM is unable to generate this as it always provides more or less a copy of the past.
The structure and functionality of EDM are explained here. And its performance is examined by means of the data sets recorded at the two climate stations Dresden and Fichtelberg over the period 1995–2014. Both stations are located in the Free State of Saxony (Germany). Dresden is a lowland station, and Fichtelberg is a mountain station with a more extreme climate. Finally, the EDM is compared to the functionality and performance of the disaggregation tool MELODIST of Förster et al. (2016).
2 Material
2.1 Case-study region
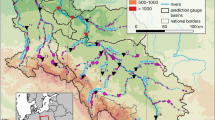
The Free State of Saxony serves as the case-study region for this work. Saxony is a federal state within Germany, covering approximately 18,400 km2 between 11.9°–15.0° E and 50.2°–51.7° N. Its topography is flat in the North and West, with low-range mountains in the South. The Ore Mountains (Erzgebirge) peak at the Fichtelberg, with heights of up to 1200 m a.s.l. Figure 1 shows the geographical locations as well as the topography of Saxony.

Geographic location and topography of the Free State of Saxony, including the geographical location of the six selected DWD climate stations
Saxony lies in the westerly wind zone of the mid-latitudes and within the transition region between the maritime climate of Western Europe and the continental climate of Eastern Europe. Its climate is dominated by the North Atlantic and the orientation of the low-range mountains due to the governing weather patterns (SMUL 2008).
Due to its climatic characteristics, the SW-NE-oriented Ore Mountains and the effects of climate change, Saxony is prone to heavy rainfall events, especially in mountainous regions with many small and medium catchments and short flood response times (SMUL 2005). The climate change also leads to water balance changes and related problems concerning water availability, distribution, storage, and usage. Therefore, water balance, flood modeling, and risk management are important fields of research in Saxony. Various models, like rainfall-runoff-models, water balance models, or flood forecasting models, exist for the river catchments in Saxony. The model WAVOS (Burek and Rademacher 2007) is used for the water level forecasting of the River Elbe. To simulate the water balance of the Mulde River catchment, the model ArcEGMO (Pfützner et al. 2007; Schumann 2009) was calibrated. The model WaSiM-ETH (Schulla and Jasper 2007) is used to estimate the water balance of the Weißer Schöps River catchment. In addition, for the rainfall-runoff-modeling of the Große Röder River catchment, the model HBV (Bergström 1992) was adapted. All these models need highly resolved input data of temperature and precipitation. The models ArcEGMO and WaSiM-ETH need data of global radiation or sunshine duration, wind speed, and vapor pressure or relative humidity.
2.2 Data
2.2.1 Observed climate data
For this study, the six climate stations Chemnitz, Dresden-Klotzsche, Fichtelberg, Görlitz, Leipzig/Halle, and Plauen of the German Weather Service (DWD) were selected as they belong to the same macro-climatic transition zone between the maritime influenced climate in Western Europe and the continental climate in Eastern Europe. Further, they also belong to the same meso-climatic zone as they are close to each other (within a radius of 125 km; Fig. 1) and within one federal state. Due to meso-climatic variations, Kronenberg et al. (2015) classified four regions of similar climates for Saxony. The climate stations used for this study spread over all these four regions. It is recommended to pool only stations of the same climate region, but this would reduce the available climate data significantly, especially concerning hourly recorded data. The consequences of pooling stations of different climate regions are discussed in Section 4.
For the comparison of the EDM with the disaggregation tool MELODIST of Förster et al. (2016), the data of the climate station De Bilt are used. This station is located in the Utrecht province, Netherlands, about 650 km to the west of Dresden. De Bilt belongs to the maritime influenced macro-climatic zone of Western Europe.
The coordinates and altitudes of all climate stations are listed in Table 1. Figure 1 shows the geographic locations of the Saxon stations. The observed hourly and corresponding daily data of the Saxon climate stations were provided by the DWD and cover the time period between September 1995 and August 2014. The datasets include the mean temperature Tmean [°C], precipitation P [mm], sunshine duration SD [min], relative humidity rH [%], and wind speed WS [m/s] at 10 m height. Additionally, the daily data also include the minimum and maximum temperature Tmin [°C] and Tmax [°C]. All of the daily data besides the precipitation data refer to 00:00 CET and 23:59 CET, where CET ≙ UTC + 1. The reference time of the daily precipitation data spans between 06:51 CET and 06:50 CET.
The hourly and daily recorded data of De Bilt were provided by the KNMI and cover the period between January 1981 and December 2014. The datasets include the same climate elements as the datasets of the Saxon stations.
A basic requirement of the model performance is the physical consistency between the hourly and the corresponding daily mean/sum data, i.e., the re-aggregation of hourly data should not result in deviations from the observed mean/sum data. To ensure this, the data were corrected for missing values in an initial step. If hourly values were missing in the data records, the corresponding gap in the model input data were encoded as − 999.0 and the related daily data were hence not used for disaggregation.
2.2.2 Objective weather pattern data
As an additional characteristic, the daily objective weather pattern (OWP) classification of the DWD is used in the present study. It consists of 40 pattern classes encompassing all atmospheric conditions. Each of these classes represents a certain combination of the general flow direction (5 mean flow directions, e.g., northwest), the synoptic flow pattern at two tropospheric pressure levels (four categories: cyclonic/anticyclonic in 950 hPa/500 hPa), as well as the humidity of the atmosphere (two categories: humid/dry), resulting in altogether 5 × 4 × 2 = 40 different OWP classes. For the case study, only the synoptic flow patterns at the two atmospheric pressure levels and the humidity of the atmosphere are used. The mean flow direction was not taken into account, due to very high effort and the lack of a semi-automated procedure to recognize the mean flow direction from weather charts.
The weather pattern is derived once a day at 12:00 CET, covers the territory of Germany and its adjacent regions, and is available since the 1st July 1979. The derivation of this classification is described in detail in Bissolli and Dittmann (2003). The OWP data are freely available online at the website of the DWD.
3 Methods
The Euclidean distance (ED) is used as a robust measure of similarity between two individual sets of daily climate data. The aim is to find the most similar analogous reference day, called “basic day” (DB) from records of historical weather events and to transfer its diurnal cycle to the “disaggregation day” (DD). The assignment of an actual event to a historical analog is the essence of the method of “analogous case”.
First, the structure of the ED model (EDM) is presented schematically in Fig. 2 and outlined below; afterwards, the methods to compare the disaggregated and observed hourly data are described.

Flowchart of the Euclidean distance model
3.1 Model structure
3.1.1 Setup of the data base
In the first step, the daily datasets of the basic climate stations and all daily data that have to be disaggregated are imported into EDM. Additionally, for each station, an accompanying dataset containing the time of the sunrise and sunset and the resulting length of the day (LOD) for each Julian day of a year is imported as a look-up table.
During the import, each basic day is assigned to each of the three incremental refining weather pattern groups WPG-1, WPG-2, and WPG-3:
-
WPG-1: subdivision with different flow patterns in the 950 hPa level (cyclonic/anticyclonic) providing two classes
-
WPG-2: subdivision with different flow patterns in the 950 hPa level (WPG-1) and additional humidity of the atmosphere (humid/dry), providing four classes
-
WPG-3: subdivision with different flow patterns in the 950 hPa level (WPG-1), humidity of the atmosphere (WPG-2) and additional with different flow patterns in the 500 hPa level (cyclonic/anticyclonic) providing eight classes
To eliminate the units of the climate elements and to achieve a dataset with an arithmetic mean of 0.0 and an empiric standard deviation of 1.0, a Studentization is done for the daily data of each element and over all stations by
where zE is the Studentized daily value of a climate element E, xE is the daily value to be standardized, \( {\overline{x}}_E \) is the arithmetic mean of the climate element over all basic stations including the station to be disaggregated, and \( {\sigma}_{x_E} \) is the standard deviation of the element over all basic stations including the station to be disaggregated.
The recorded hourly datasets of some climate elements, e.g., precipitation and relative humidity, are not normally distributed and it is not assumed to obtain normality by this Studentization.
Afterwards, to make the climate elements comparable among each other, all Studentized data are standardized by dividing each Studentized daily value, zE , by the range of all the data:
where \( {z}_{E_s} \) is the standardized-Studentized daily value of a climate element E, zE is the Studentized daily value, and \( \underset{j=1..i}{\min }{z}_E(j) \) and \( \underset{j=1..i}{\max }{z}_E(j) \) are the minimum and maximum values determined over all climate elements, all stations and all days.
The following steps are carried out separately for each disaggregation day DD.
3.1.2 Selection of an analogous day
If the data of the station to be disaggregated are within the pool of basic days DB (i.e., for validation as shown in Section 4.3), the specific day DD is excluded to avoid a disaggregation of a day with its own data. The performance appeared better when the three preceding and the three subsequent days next to DD are excluded.
In the first selection step, all basic days DB in the pool are filtered according to two constraints. If the DD is a precipitation day with P > 0.0 mm, the most similar DB has to be a precipitation day, too, and if DD has a sunshine duration > 0.0 h, the most similar DB has to have a sunshine duration of > 0.0 h, too.
Afterwards, the standardized-Studentized daily data of the selected analogous DB are used to calculate the similarity metrics ED as follows:
where zs is the standardized and Studentized daily value, subscript E denotes the climate element, index i is the identifier of the climate element (here e.g., E1 means the maximum temperature), subscript B refers to the basic daily data, and subscript D to the daily data to be disaggregated.
The ED is calculated only for all those filtered DB that contain no missing values in the data of the climate elements that are used for the ED calculation or that have to be disaggregated.
The subsequent selection of the most similar DB is based on the minimization of ED values.
The model performs two different stepwise selection approaches to filter out the most similar day, both comprising five steps.
The first selection approach is stepwise filtering the DB applying a successively refined LOD interval (Selection 1, S1):
-
1.
LOD ± 2 h of the DD
-
2.
LOD ± 1 h of the DD
-
3.
LOD ± 30 min of the DD
-
4.
LOD ± 15 min of the DD
-
5.
Same LOD of the DD
If more than one DB is left after a selection step, the next step is performed. Otherwise, if only 1 day is left, this day is adopted the most similar day and hence, is used as DB for the disaggregation (DBD). In addition, if no DB is left after a selection step, the most similar day is selected from all the DB that were remaining after the prior step. Then, the most similar DB will be used as DBD and has a minimum distance (EDmin).
The second (alternative) selection approach is stepwise filtering the DB by applying the successively refined LOD (cf. S1) and a successively extending OWP criteria (Selection 2, S2):
-
1.
LOD ± 2 h of the DD and:
-
1.1.
Exact same WP
-
1.2.
WPG-3
-
1.3.
WPG-2
-
1.4.
WPG-1
-
1.1.
-
2.
LOD ± 1 h of the DD and:
-
2.1.
Exact same WP
-
2.2.
WPG-3
-
2.3.
WPG-2
-
2.4.
WPG-1
-
2.1.
-
3.
LOD ± 30 min of the DD and:
-
3.1.
Exact same WP
-
3.2.
WPG-3
-
3.3.
WPG-2
-
3.1.
-
4.
LOD ± 15 min of the DD and:
-
4.1.
Exact same WP
-
4.2.
WPG-3
-
4.1.
-
5.
Same LOD of the DD and:
-
5.1.
Exact same WP
-
5.2.
WPG-3
-
5.1.
If no DB is left after a selection step, the next step is performed. If only 1 day is left, this is adopted the most similar day and hence is used as DB for the disaggregation (DBD). In addition, if more than one DB is left, the most similar DB will be used as DBD and has a minimum distance EDmin as written in Eq. 3.
It is possible that there is more than one DB with EDmin, especially when only a few or even only one element is used for the ED calculation. In this case, the DBD is selected by means of a uniformly distributed random factor.
3.1.3 Adaptation of the selected hourly meteorological conditions
To ensure self-consistency between aggregated and disaggregated data, an intermediate adjustment step is necessary. Prior to application to DD, the diurnal cycle of the most similar DB is rescaled. The rescaling procedure starts with the calculation of the ratios of the daily values of each climate element besides temperature; for temperature, the difference is calculated. These two factors are equal to
where RE is the ratio of the climate element E, ED is the daily value of the climate element E that has to be disaggregated, EB is the basic daily value of the climate element E of the most similar day (DBD), and ΔT is the difference between the daily mean temperatures of the disaggregation day (TD) and the most similar basic day (TB).
With these two metrics, the hitherto unknown hourly values of the disaggregation day are generated by applying them to the known hourly values of the identified analogous DBD as follows:
where EDhr is the generated hourly value of the climate element, EBhr is the hourly value of the climate element of the DBD, TDhr is the generated hourly mean temperature, and TBhr is the hourly mean temperature of the DBD.
Due to multiplication with the scaling RE, it is formally possible that non-physical hourly sunshine durations of > 60.0 min and relative humidities of > 100.0% are generated. In this case, the sunshine duration is set to 60.0 min and the relative humidity is set to 100.0%.
Daily precipitation and sunshine duration values of 0.0 mm and 0.0 min are not disaggregated. Instead, the related 24 hourly values are set equal to 0.0 mm and 0.0 min, respectively.
If the DD contains a missing value of a climate element that is not included in the ED calculation, the missing value is replaced with 24 hourly missing values for this climate element. However, if this climate element is included in the ED calculation, it leads to missing hourly values for all the climate elements.
3.1.4 Treatment of hours with precipitations > 0 mm and 60 min of sunshine
Disaggregation might result in simultaneous co-occurrence of rain events and clear-sky conditions in the hourly data. Of course, rain and sunshine might be observed simultaneously at characteristic time scales shorter than 1 h, e.g., during convective rainfall events in postfrontal cold airmasses with partial cloud coverage and sunny episodes, particularly in summer (frequently associated with the appearance of rainbows). Unfortunately, the retrieval of such short-term variability from the hourly data the historical records are based on requires the solution of a closure problem, which is even trickier than the disaggregation of hourly data from daily values (as in the present study). While consideration of subscale cloud variability would be a promising task for model refinement, its realization was far beyond the scope of the present analysis. Focusing on the characteristic conditions revealed in records of hourly values, here we make use of the ad hoc assumption that coinciding rain-sunshine events should be excluded, i.e., there is either precipitation or sunshine. The disaggregated hourly data of the sunshine duration are corrected for the related hourly precipitation amounts to avoid a sunshine duration of 60.0 min coinciding with a precipitation value of > 0.0 mm. The applied rescaling algorithm is realized via the following nine steps:
-
1.
Since the reference time intervals of the daily precipitation sum and sunshine duration differ, the recorded data are projected into the same time interval. Auxiliary daily precipitation sums (Paux) are calculated for the time spans from 00:00 CET to 23:59 CET for both the DBD (PauxB) as well as for the DD (PauxD).
-
2.
The theoretical possible precipitation hours are calculated for DBD and DD as follows:
with PPHB as the possible precipitation hours of the basic day, SDB as the daily sunshine value of the basic day, and PPHD as the possible precipitation time of DD and SDD as the daily sunshine value of DD.
-
3.
For the DBD and the DD, averaged daily precipitation intensities are calculated by
with PIB and PID denoting the mean precipitation intensities of the most similar basic and disaggregation day, respectively.
-
4.
Then, a precipitation intensity ratio PIF is calculated by dividing the two precipitation intensities:
-
5.
The possible numbers of minutes with precipitation for the hour to be corrected are calculated according to:
where PPMB is the possible number of precipitation minutes of the basic hour, and SDBhr is the sunshine duration of the basic hour.
-
6.
The averaged precipitation intensity of the basic hour PIBhr is calculated by dividing the precipitation value of the basic hour PIBhr by PPMB:
-
7.
The averaged precipitation intensity for the generated hourly precipitation value is obtained by multiplying PIBhr with the ratio PIF:
-
8.
Knowing \( {PI}_{D_{hr}} \), the number of precipitation minutes for the generated hourly precipitation value is calculated as follows:
where PMD is the number of precipitation minutes of the generated hour and PDhr is the generated hourly precipitation amount.
-
9.
Finally, the number of sunshine minutes SMD for the hour to be corrected results from the difference of 60.0 min and the PMD as follows:
The corrected hourly value of sunshine duration is only accepted if it is smaller than the value calculated by using the ratio (Eq. 6).
After this final data adjustment, the process restarts with the next disaggregation day. When the disaggregation of all days is finished, the model creates an output file containing the disaggregated hourly values for all days and climate elements.
3.2 Comparison of disaggregated and observed hourly data
The disaggregated and observed hourly data are compared by using Taylor diagrams, quantile-quantile plots (Q-Q plot), additional statistical values, and the mean diurnal and annual variations. Since the days without precipitation (P = 0.0 mm/d) or measurable sunshine duration (SD = 0.0 min) were not disaggregated, they were not included in the comparison.
Taylor diagrams (Taylor 2001) were plotted for the elements Tmean, SD, rH, and WS as they allow good simultaneous visual comparison of three statistical measures. Here, the measures of the Pearson correlation coefficient (r), normalized root mean square difference (RMSDn), and normalized standard deviation (σn) were used.
For the comparison of the disaggregated and observed hourly precipitation data, Q-Q plots of two variables were chosen. Additionally, the lines for the quantiles of 50%, 75%, 90%, 95% (heavy precipitation), and 99% (extreme precipitation) were added to the plots.
In addition to the values used for the Taylor diagrams and Q-Q plots, the statistical values minimum (xmin), maximum (xmax), mean (\( \overset{\sim }{x} \)), median (xmed), and 95% quantile (x95%) were calculated.
To analyze whether the disaggregated data reproduce the general basic characteristics of the observed data, the mean diurnal and annual variations are compared in three ways. The diurnal variations of the four climate elements T [°C], SD [min], rH [%], and WS [m/s] are compared by calculating the diurnal cycles based on the observed and disaggregated hourly data. In addition, the annual variations of each climate element were compared by means of annual cycles calculated from the aggregated observed and generated monthly data.
To compare the results delivered by the EDM with those of the tool MELODIST, the root mean square error (RMSE) was calculated. Further, five major characteristics of hourly precipitation features of the observed and generated data for the stations De Bilt and Dresden were calculated: mean duration of events [h], mean precipitation sum of events [mm], mean duration of dry spells [h], number of events per year, and number of hours with P > 0.0 mm per day.
4 Results and discussion
The disaggregated climate data are analyzed for the two climate stations, Dresden and Fichtelberg. Both stations belong to different regions of similar climate after Kronenberg et al. (2015). Dresden is a lowland station and was selected because it has the best data base. Fichtelberg was selected because it is a mountain station with a more extreme climate and it serves hence as a kind of test for the performance of the EDM. The consequences of pooling stations of different climate regions are discussed in this section.
The results for both stations are analyzed for various aspects. The differences concerning whole years, summer and winter half-years, the influence of the stations used as base stations, the effects of the climate elements used, and the mean diurnal and annual variations of the generated data are considered.
4.1 Generated datasets based on five stations
At first, the data for the whole period September 1995–August 2014 are analyzed. These data were generated by using the observed data of five basic stations. In order to prevent a skill overestimation, the data of the station which is subject of disaggregation were not considered in the evaluation of the pool of basis data. This means that the data for the climate station Dresden and Fichtelberg, presented here, are generated without Dresden and Fichtelberg, respectively.
4.1.1 Climate station Dresden
Figure 3 shows the Taylor diagram and the Q-Q plot for climate station Dresden for both selection approaches S1 and S2, respectively. The corresponding statistical values are shown in Table 2. It can be seen that the results of all climate elements show normalized standard deviations close to 1.0 for S1 as well as for S2.

(left) Normalized root mean square difference [-], normalized standard deviation [-] and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] for the climate station Dresden based on five stations
The temperature values of both selections show the best performance with the very high correlations of 0.98 and 0.99 and very low RMSDn values of 0.19 and 0.15. This results from the homogenous, sinusoidal character of the diurnal cycle of the temperature, which is properly reproduced by EDM. In contrast to temperature, the wind speed has a more stochastic character with larger and irregular diurnal variations. Hence, worse results are provided for the wind speeds with correlations of 0.73 and 0.79 and RMSDn values of 0.76 and 0.67. The results of the generated sunshine duration are very similar to those of the wind speed. The sunshine duration is strongly correlated with the highly fluctuating cloud cover, i.e., it is also characterized by possible high variations during the day. Such variations lead to more frequent and greater differences between the observed and generated hourly values. Since the relative humidity is characterized by a more homogenous diurnal cycle (essentially affected by the course of the temperature), these results reveal higher correlations of 0.88 and 0.91 and lower RMSDn values of 0.48 and 0.42.
The application of the rescaling procedure according to Section 3.1.3 to hourly rH values results in a cut-off of respective 3780 (S1) and 2844 (S2) generated hourly values to the maximum possible value of rH = 100%, corresponding to correction rates of 2.3% (S1) and 1.6% (S2), respectively. Correction of hourly data applies to 783 (11.6%) and 620 (9.2%) disaggregated days, respectively.
Analogously for SD, 8917 (S1) and 8564 (S2) generated hourly values were constrained to the maximum value of 60.0 min, corresponding to correction rates of 11.1% (S1) and 10.7% (S2). The corrected values affect 1970 (29.2%) and 1856 (27.5%) disaggregated days, respectively.
The correction to exclude co-occurrence of rain events and clear-sky conditions according to Section 3.1.4 applies to 601 (S1) and 526 (S2) generated hourly SD values, respectively. These corrections affect 418 (6.2%) and 366 (5.4%) days, respectively. As a result of these two corrections, the calculated daily sums differ from the observed daily values. The maximum differences amount to − 4.5 h (S1) and − 3.4 h (S2), but 89.8% (S1) and 94.2% (S2) of the affected days show only small differences in the range of − 1 h < SD ≤ 0.0 h, i.e., of less than 1 h.
In the right panel of Fig. 3, the quantiles of the generated precipitation data are shown. Up to the 96% quantile, the quantiles differ only between 0.1 and 0.3 mm/h. For the quantiles ≥ 96%, representing heavy and extreme precipitation, the differences increase to 0.9 mm/h (S1) and 0.7 mm/h (S2), and the overestimation amounts to 15% (S1) and 12% (S2). There are various potential reasons for the overestimation. Both generated datasets contain less hourly values of > 0.0 mm/h (Table 2) which indicates that the EDM tends to generate shorter and less precipitation events (cf. Section 4.7). This results from rounding very small intensities to 0.0 mm/h and from a potential tendency of the EDM to select a day with a shorter precipitation event as the most similar day. The rounding of the disaggregated hourly intensities itself might be a reason for the differences of the observed and disaggregated intensities. Further, in this analysis, precipitation is one of seven equal-weighted climate elements included in the calculation of ED, i.e., precipitation has an impact of 1/7 of the selection of the most similar day. If the impact would be higher, the results are expected to improve for the quantiles. This is examined in Section 4.4. Last but not least, there are supposed to be unintended influences of other variables used in the EDM resampling.
To quantify the magnitude of the overestimation of the quantiles, it was examined whether the overestimation lays within the confidence interval of an extreme value statistics as used for engineering design and flood simulation. For example, the precipitation intensity of 7.0 mm/h corresponds to a return period of 0.2 a, which means such intensities are likely to be observed 5 times per year at the station Dresden. A confidence interval of [5.04 mm/h, 9.15 mm/h] was estimated through fitting of a Gumbel distribution to the hourly data and assuming a critical value of t95.2 = 2.95 from the Student’s t distribution. The observed difference [0.9 mm/h] of the 0.99-quantile lays therefore within the confidence interval of the fitted extreme value distribution for design rainfall (Fig. 4).

Confidence interval for the observed precipitation intensities [mm/h] of station Dresden
For all elements, Fig. 3 and Table 2 show that the results of S2 fit better than those of S1, but the differences are very small. Hence, including the OWP for the selection of the most similar basic day leads to only weak improvements.
The statistical values contained in Table 2 but not shown in Fig. 3 exhibit high correspondence for all elements besides the minimum of rH of S1 (14.3%) and the maximum P of both selections (48.6 mm/h).
4.1.2 Climate station Fichtelberg
The statistics for climate station Fichtelberg (Fig. 5, Table 3) show similar results to those of the climate station Dresden, with normalized standard deviations close to 1.0 for all elements and both selections. The best results, with a correlation of 0.97 and RMSDn of 0.25, are again obtained for the generated temperature data. The worst results are obtained again for the sunshine duration and the wind speeds with correlations between 0.68 and 0.74 and RMSDn between 0.74 and 0.81. The median of the observed SD (15.0 min) is highly underestimated by S1 (8.5 min) and S2 (10.0 min) (Table 3). The observed maximum wind speed (30.1 m/s) is highly overestimated, with 59.0 m/s and 45.7 m/s. In comparison to the Dresden station, the generated relative humidity data show slightly worse results. These findings point to the influence of meso-climatic variations in the study region, that were not included in the present analysis.

(left) Normalized root mean square difference [-], normalized standard deviation [-], and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] for climate station Fichtelberg based on five stations
The application of the rescaling procedure according to Section 3.1.2 to hourly rH values results in a cut-off of respective 21,916 (S1) and 22,528 (S2) generated hourly values to the maximum possible value of rH = 100%, corresponding to correction rates of 22.1% (S1) and 22.8% (S2), respectively, which is much higher than for the representative low-land station Dresden. Concerning SD, 8162 (S1) and 8042 (S2) generated hourly values were reduced to the maximum value of 60.0 min. This corresponds to correction rates of 16.1% (S1) and 15.8% (S2). The corrected values affect 1771 (42.9%) and 1615 (39.2%) disaggregated days, respectively.
The correction to exclude co-occurrence of rain events and clear-sky conditions according to Section 3.1.4 applies to 800 (S1) and 496 (S2) generated hourly SD values, respectively. This correction affects 460 (11.2%) and 292 (7.1%) days, respectively. As a result of these two corrections, the calculated daily sums differ from the observed daily values. The maximum differences amount to − 6.6 h (S1) and − 7.0 h (S2), but 77.1% (S1) and 83.7% (S2) of the affected days show only small differences in the range of − 1 h < SD ≤ 0.0 h, i.e., of less than 1 h.
As for the lowland station Dresden, the inclusion of the OWP improves the results slightly.
Concerning the quantiles of the generated precipitation data (Fig. 5 (right))), both selection approaches tend to overestimate, and the OWP inclusion leads to even higher overestimations. This is a clear indication of significant mesoscale variability in the study region that segregates the climate conditions at the Fichtelberg station from those of the other five stations. In addition, EDM tends to prefer days with convective precipitation events to reproduce the higher daily precipitations at station Fichtelberg, but this leads to an overestimation of the hourly values. For the quantiles ≥ 93%, the overestimations increase to maxima of 0.7 mm/h (S1) and 1.5 mm/h (S2), and the overestimation amounts increase to 12% (S1) and 26% (S2). For potential reasons for the overestimation, compare to the analysis in Section 4.1.1.
4.2 Summer and winter half-years
The generated data of the stations Dresden and Fichtelberg are analyzed separately for the summer and winter half-years based on five climate stations (cf. Section 4.1). The summer half-year covers the 6 months from April to September, and the winter half-year covers the months between October and March. These both half-years are analyzed since they differ in their climatic characteristics. Due to higher global radiation and temperatures, the summer half-year is characterized by more convective and unstable weather patterns while the winter half-year is predominated by more stable weather patterns. This causes different diurnal cycles of the climate elements, especially of precipitation. While convective (heavy) precipitation events tend to short durations of one or only a few hours, stratiform (heavy) precipitation events tend to longer durations of up to a few days.
The results for the climate elements T, SD, rH, and WG reveal essentially the same basic characteristics for both, the half-years and the whole year (cf. Section 4.1) for both stations (see Fig. 11 (left) and Fig. 12 (left) and Tables 8, 9, 10, and 11 in the Appendix). The temperature data were found to fit best the wind speed and sunshine data fit worst and those of the relative humidity are in between. The inclusion of the OWP leads to small improvements for these five climate elements of both half-years.
The climate elements with homogenous diurnal cycles (T, rH) are well reproduced for the summer as well as for the winter half-years. In contrast, the climate elements with higher hourly variations (SD, WS) are less well reproduced in general but perform slightly better for the winter months. This result suggests that the basic assumptions of the disaggregation procedure (e.g., the exclusion of coincidental sunshine and precipitation) are better fulfilled in the wintertime with less scatter in the data caused by convective clouds, turbulence, and unstable weather conditions.
Concerning precipitation, the results differ between Dresden and Fichtelberg. For Dresden, the improved reproductions for the winter half-year also apply to the precipitation data (Fig. 11 (right) in the Appendix), explainable by the lower rain intensities and lower frequency of convective rainfall events during these months. For Fichtelberg, the generated data show overestimations for both half-years, especially for the quantiles ≥ 95% (Fig. 12 (right) in the Appendix). This overestimation is distinct higher for the winter months. For the high daily precipitation sums at station Fichtelberg, the EDM tends to prefer days with convective weather conditions and hence higher precipitation rates per hour. Further potential reasons for the overestimation are given in Section 4.1.1.
The inclusion of the OWP leads to small improvements for both half-years at the station Dresden. But at the station Fichtelberg, it worsens the performance of the quantiles of both half-years. This is supposed to be a consequence of the neglect of the meso-climatic variability in the setup of the pool of basic data. While the OWP conditions might apply to all included stations, orographic effects might cause differences in the statistical precipitation response from one station to another. As the climate station Fichtelberg, the only mountain station in the pool, was excluded in this analysis from the pool of basis data, the EDM could only select a “most similar event” of a lowland station.
4.3 Data generation based on the full dataset
In this section, it is examined how the results change if the data of all six Saxon basic stations are used, i.e., the stations Dresden and Fichtelberg were included as basic stations, too.
In comparison to the results discussed in Section 4.1.1, the results for station Dresden are at least identical for all five climate elements (see Fig. 13 (top) in the Appendix). This suggests that the basic stations Görlitz, Chemnitz, Leipzig, and Dresden belong more or less to the same mesoclimate-tope. Hence, the inclusion of station Dresden as an additional basic station does not lead to a substantial gain in physical information and to an improvement of the overall EDM performance. For all elements, the results of S2 performs better than those of S1, though the differences are small.
In contrast, the inclusion of the station Fichtelberg as a basic station leads to small improvements for the relative humidity, the sunshine duration, and the wind speed for Selection S1 (Fig. 13 (bottom, left) in the Appendix). The precipitation quantiles of S2 are overestimated to the same amount as for S2 as discussed in Section 4.1.2. However, for S1, the overestimation increases by 0.2–0.3 mm/h for the quantiles ≥ 90% (Fig. 13 (bottom, right) in the Appendix). Furthermore, the inclusion of the OWP leads again to higher overestimations of the quantiles although the station Fichtelberg is included (cf. Section 4.1.2).
4.4 Sensitivity of the distance metrics against the number of considered climate elements
To examine the influence of the climate elements used for the calculation of the ED, the disaggregation for the stations Dresden and Fichtelberg was performed by using only the mean temperature and the precipitation amount to calculate the ED. These two climate elements were selected as they are the most frequently available observed elements. The statistical results are shown in Fig. 6. Since the relative humidity, the sunshine duration, and the wind speed were not used for the ED calculation, their statistics show obviously worse results for both stations and both selection approaches (Fig. 6 (left)). The temperature data fit also slightly worse because the minimum and maximum temperature were not included in the ED calculation. However, the quantiles of the precipitation data show better results for both stations and both selection approaches (Fig. 6 (right)). For station Dresden, the quantiles show almost perfect agreements with the observed quantiles. This is caused by the selection of the most similar day based on the two climate elements. Hence, the impact of precipitation in an ensemble of only 2 climate elements corresponds to a weight of 1/2, and in an ensemble of 7 elements (Sections 4.1–4.3) to a weight of only 1/7.

(left) Normalized root mean square difference [-], normalized standard deviation [-], and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] at climate stations Dresden (top) and Fichtelberg (bottom) based on six stations and the calculation of ED using only T and P
For climate station Fichtelberg, the inclusion of the OWP leads to equal or even worse results, e.g., of the precipitation quantiles. Again, this is caused by the fact that for the same OWP, the climate characteristics at station Fichtelberg differ from those of the other five stations.
4.5 Mean diurnal cycles
The mean diurnal cycles are analyzed to examine whether the mean daily statistics and variations are preserved by EDM. The diurnal cycles were determined for the temperature, the sunshine duration, the relative humidity, and the wind speed by calculating the daily means or sums based on the observed and generated hourly data of the years 1995–2014. Afterwards, the mean values were calculated for each hour of the day.
Figure 7 shows the mean diurnal cycles of the four climate elements at climate station Dresden. For the temperature, the sunshine duration, and the relative humidity, the mean diurnal cycles based on the generated data agree with those based on the observed data. Only for the wind speed, the diurnal cycles of the generated data show an underestimation during the night and an overestimation during the day. However, these are both very small and negligible, with maximum differences of − 0.2 m/s and 0.2 m/s, respectively. The strong results are caused by the similar climate conditions of the used basic climate stations (cf. Table 1). Furthermore, it becomes apparent that the two corrections of the sunshine duration and the correction of the relative humidity have no influence on the mean diurnal cycle.

Mean diurnal cycle of T [°C], SD [min], rH [%], and WS [m/s] of the observed data and the generated data of Selection 1(S1) and Selection 2 (S2) at climate station Dresden based on five stations
The mean diurnal cycles of the four climate elements at climate station Fichtelberg are shown in Fig. 8. In contrast to station Dresden, the mean diurnal cycles of station Fichtelberg have a worse agreement for all elements and both selection approaches. The mean temperature is overestimated for each hour, while the highest differences occur in the early afternoon. Concerning the sunshine duration, the mean diurnal cycles of the generated data give a slight overestimation for the daytime hours. During the nighttime hours, there are no differences because these hours are automatically set to 0.0 min. A distinct underestimation occurs in the relative humidity data of both selections. The highest differences occur for the afternoon hours and amount to − 10%.

Mean diurnal cycle of T [°C], SD [min], rH [%], and WS [m/s] of the observed data and the generated data of Selection 1 (S1) and Selection 2 (S2) at climate station Fichtelberg based on five stations
The diurnal cycle of the wind speed at the climate station Fichtelberg is characterized by a maximum during nighttime and a minimum during the afternoon, which is in line with empirical findings on the wind behavior at mountaintops (cf. Blüthgen and Weischet 1980; Stull 2000).
However, for wind speed, both EDM selection approaches deliver diurnal cycles which are inverse to the observed one, with an overestimation in the afternoon and an underestimation at nighttime. The underestimation is greater but still small, with deviations from the observed values up to − 2.2 m/s (S1), and the overestimation amounts to only 1.4 m/s (S1). The inversion of the diurnal cycle is caused by the differences in the climate characteristic between the station Fichtelberg and the other five climate stations. An analysis of the disaggregation of the dataset of Fichtelberg by using only Fichtelberg itself as basic station showed that the inverse diurnal cycle is then reproduced by the EDM.
Hence, the EDM in its current stage of development is not yet able to reproduce such an inverse cycle when the basic stations are not characterized by similar climate conditions. These differences in the climate conditions of the basic stations are also the reason for the over- and underestimations of the other three climate elements. The diurnal cycle of the observed basic values should fit the diurnal cycle of the disaggregated station. Therefore, the model application is restricted to basic data representing similar climatic conditions.
4.6 Mean annual cycles based on mean monthly values
Comparable to Section 4.5, in this section, the mean annual cycles of all climate elements, including precipitation, are analyzed. The mean monthly data were calculated based on the observed and generated daily data.
The generated mean annual cycles are almost identical to the observed cycles for all climate elements at station Dresden (Fig. 9). This is caused by the preservation of the daily sums or means of the climate elements, which is a basic function of EDM. The small differences of the sunshine duration and the relative humidity result from the corrections implemented in EDM (cf. Section 3.1).

Mean annual cycle of T [°C], P [mm] SD [min], rH [%], and WS [m/s] of the observed data and the generated data of Selection 1 (S1) and Selection 2 (S2) based on aggregated mean monthly values at climate station Dresden based on five stations
In general, these findings also apply to the annual cycles at climate station Fichtelberg (Fig. 10), but the underestimations of the mean monthly sunshine duration and relative humidity are greater since more days are affected by the corrections (cf. Section 4.1.2). Furthermore, there are greater differences for all elements due to the different climate characteristics of the basic stations.

Mean annual cycle of T [°C], P [mm] SD [min], rH [%], and WS [m/s] of the observed data and the generated data of Selection 1 (S1) and Selection 2 (S1) based on aggregated mean monthly values at climate station Fichtelberg based on five stations
4.7 Functionality and performance of the EDM in comparison to MELODIST
To further assess the performance of the EDM and the quality of the generated datasets, a comparison with the MEteoroLOgical observation time series DISaggregation Tool (MELODIST) developed by Förster et al. (2016) is made in this section. MELODIST is a robust, reliable, and transferable tool to disaggregate daily time series of the climate elements T, rH, WS, P, and shortwave radiation. Physical consistency among the climate elements is not inherent in the methodology of MELODIST as it disaggregates each element independently. Most of the climate elements are disaggregated by using parsimonious methods with basic levels of complexity. The daily values of T are disaggregated using a cosine function with Tmin at the time of sunset and Tmax 2 h after sun noon. For disaggregating rH, the model generates hourly values of dew point temperature. Similar to the disaggregation of T, the values of WS are disaggregated by means of a cosine function. And for the disaggregation of P, the multiplicative cascade model after Olsson (1998) was applied.
For this comparison, the daily data of the climate station De Bilt were disaggregated two times for the validation period, January 1991–December 2014 (Förster et al. 2016), firstly, by using De Bilt as sole basic station (dataset “EDM De Bilt”), and secondly, by using the six Saxon stations as basic stations (dataset “EDM Sax”). As De Bilt was disaggregated with itself as basic station, the same procedure was done for Dresden (dataset “EDM Dresden”) and the results are compared to those in Section 4.1.1 (dataset “EDM Sax”).
Following the analyses of Förster et al. (2016), the statistical values \( \overset{\sim }{x} \), σ, RMSE, and r were calculated for T, rH, and WS (Tables 4, 5, 6), and for P, five major characteristics of hourly precipitation features of the observed and generated data were calculated (Table 7).
It can be seen, that EDM and MELODIST perform equal for the disaggregation of T for station De Bilt. The statistics show only small differences for RMSE with slightly worse results for the two data sets generated by the EDM (Table 4). Concerning station Dresden, the EDM performs also very well due to the very homogeneous diurnal cycle of T (cf. Section 4.1). Hence, for the disaggregation of T, also, a parsimonious method is sufficient (MELODIST).
Concerning the disaggregation of rH for De Bilt, EDM performs better than MELODIST, with distinct higher correlations and smaller RMSE, and also smaller standard deviations (Table 5). For station Dresden, the results are similar for both disaggregations with slightly smaller RMSE, smaller standard deviation, and slightly higher correlation for the data set “EDM Sax S1.”
The correlations of the disaggregated WS for De Bilt are distinctly higher for the EDM datasets; although, the RMSE are higher (Table 6). For station Dresden, the correlation is slightly higher for the dataset “EDM Sax S1”.
For station De Bilt, the results for P show that MELODIST overestimates the mean duration of precipitation events and underestimates the number of precipitation events per year. In contrast, EDM generates shorter durations of precipitation events, less numbers of precipitation events per year (data set “EDM Sax S1”), and less numbers of hours with P > 0.0 mm/h per day while the mean precipitation sum of events is conserved. The results for Dresden reveal that EDM tends to underestimate the duration and numbers of precipitation events as already assumed in Section 4.1.
It can be summarized that both disaggregation tools perform comparable for each climate element while both show some limitations. But the high benefit of the generated datasets of EDM is the physical consistency over all climate elements.
5 Summary and conclusions
In this paper, the structure and results of a newly developed multivariate non-parametric resampling model, the Euclidean Distance Model (EDM), for the hourly disaggregation of daily climate data are presented. As a case study, six climate stations located in the Free State of Saxony (Germany) were selected. The daily climate data of stations Dresden and Fichtelberg were exemplarily disaggregated for the years 1995–2014 and compared to the observed hourly data.
The generated datasets that were disaggregated by using alternatively either five or six basic stations show very similar results and strong agreements for all the studied climate elements. The inclusion of the disaggregated station itself into the pool of basic stations leads to some improvements of the model performance. These improvements are greater when the other basic stations are characterized by different climate conditions, as is the case for the mountain station Fichtelberg. It is shown that the results always fit better for such climate elements, which are characterized by a homogenous diurnal cycle that is well reproduced by EDM. Hence, each generated dataset shows the best results for temperature and the worst for wind speed and sunshine duration.
Concerning precipitation, EDM tends to overestimate the quantiles of the hourly data, especially for heavy and extreme values (quantiles ≥ 90%). There are various potential reasons for this. (i) The EDM tends to generate less and shorter precipitation events. This might be due to rounding small intensities to 0.0 mm/h and a preferred selection of basic day with less or shorter precipitation events. (ii) The rounding of the disaggregated hourly intensities itself. (iii) The equal-weighted impact of precipitation in the calculation of the ED. (iiii) The pool of heavy and extreme precipitation events is significantly smaller. (iiiii) There are supposed to be unintended influences of other variables used in the EDM resampling.
An exemplarily investigation of the magnitude of overestimation in terms of a confidence interval of an extreme value statistic as used for engineering design and flood simulation showed that the differences of the quantiles lay within the confidence interval of the fitted extreme value distribution for design rainfall. Hence, the uncertainty of the estimation of design rainfall is much higher, than the uncertainty of the EDM model. However, the differences should be investigated and validated in each case of an EDM application.
The overestimation might be an advantage in the field of hydroengineering. Since an increase in the hourly intensity of heavy precipitation events is already observed and is expected to continue in the future, such overestimation anticipates this trend. But of course, the higher costs of hydroengineering by using these higher intensities have to be weighed against the benefits, e.g., the benefits of higher flood protection. However, with regard to error propagation and unwanted biasing of post-calculated cost functions in optimal decision strategies, the underlying models such as EDM should advantageously be free of any bias.
Furthermore, it is shown that, for all datasets, the inclusion of the OWP in the selection of the most similar day leads to small improvements for all climate elements besides the precipitation quantiles for station Fichtelberg. Here, the OWP causes even a worsening of the results, which is caused by the disregard of the meso-climatic variations within the investigated territory and their impact on the setup of the basis data pool. Furthermore, the worsening results from smaller data pool for events with heavy precipitation. Therefore, the OWP are not mandatory to obtain accurate hourly data. It remains to be investigated whether a more sophisticated OWP approach based on a refined similarity metrics on the base of further meteorological field observations can enhance the EDM skill. It is expected to improve the performance of the EDM by taking the mean flow directions into account as they have a high impact on the humidity and temperature of an airmass. Hence, they are an important indicator for the (expected) weather situation, e.g., they impact the precipitation events due to possible luv-lee effects.
The analyses for the summer and winter half-years reveal that EDM delivers better results for the winter half-year. This applies to both analyzed stations and all climate elements besides the precipitation for station Fichtelberg due to different climate characteristics at this mountain station. For the summer half-year, slightly worse results are shown for both analyzed stations due to the increased turbulence and unstable weather conditions during these months.
The results for the disaggregation using only the temperature and precipitation for the calculation of ED reveal that the generated data fit better if the climate element is involved in the calculation of the ED. In addition, the fewer elements used, the better the fit of the results of the used elements as their influences on the selection of the most similar day are increased.
Due to the functionality of EDM, the daily sums or means of the climate elements are conserved. This leads to an exact reproduction of the mean diurnal cycle if the used basic stations show similar climate characteristics. If this is not the case, as shown for station Fichtelberg, there are some over- and underestimations of all elements and even an inversion of the diurnal cycle of the wind speed.
Concerning the mean annual cycles based on the mean monthly values, EDM delivers an accurate reproduction for each climate element. For the mean annual cycles, the different climate characteristics of the used stations have lower effects.
An additional comparison of the functionality and performance of the EDM to the tool MELODIST, showed that the EDM delivers comparable results for all disaggregated climate elements. Both tools have their limitations, but the physical consistency over all disaggregated climate elements is a high benefit of EDM. Therefore, these generated datasets might be more suitable as input data for hydrological or ecological modeling.
EDM is a very robust and flexible model that can be applied to any climate station if hourly data are available within the same climate region. This method works with several climate elements as well as with only one climate element. EDM delivers data with strong correlation to the observed data, maintaining their statistical characteristics, and the delivered hourly data set is physical consistent over the disaggregated climate elements. Additionally, a technical advantage of EDM is its efficient computing performance and that there is no time-consuming calibration needed.
However, there are also some restrictions in the application of this model. (i) The basic climate stations should have similar climate conditions to those of the target station. (ii) EDM also requires a sufficient data base of (continuously) recorded hourly data.
The climate stations used for this study were selected as they belong to the same macro- and meso-climatic zone and as they are close to each other. It is recommended to preferably pool only stations of only one region of similar climate, e.g., as classified by Kronenberg et al. (2015), but usually this means a significant reduction of available climate data, especially concerning hourly recorded data. Although the selected climate stations spread over four climate regions, the climate characteristics of the stations were similar enough to achieve high correspondence of the observed and generated hourly data besides some restriction for the mountain station Fichtelberg.
How many basic data are sufficient cannot be clearly defined. The EDM works independently of the amount of basic data. The disaggregation with only one basic station was tested for the comparison with the tool MELODIST, and the results showed no distinct worsening. However, for analyses with climatological context, a data base covering 30 continuous years (climatological period) would be required. But regarding the real spatio-temporal data availability, at least 10 years of continuously recorded data are required. Of course, the more basic data are available the better the disaggregated data correspond and the more the generated diurnal cycles vary.
Finally, but importantly, since EDM is a resampling model and uses the observed diurnal cycles of the past, the generated hourly data are more or less a copy of the past. The applied offset or boost factors for new “records” in the target time-series, however, allow the generation of data which have not yet been observed. Therefore, the model is capable of taking future trends (like climate change) into account; it can disaggregate daily data from statistical downscaling (as, e.g., WETTREG, Enke et al. 2005; Kreienkamp et al. 2010) of climate projections. Such a model chain allows impact modeling with hourly input requirements and might allow the analysis of future extremes by changing the occurrences of the observed extremes. Including generated future OWP would improve the results of the disaggregation of future climate data because changes of the frequencies of the weather patterns are expected due to climate changes. But their generation is extremely complex and time-consuming. Future OWP time series exist for Germany and Saxony after the classification of Enke et al. (2005). For Germany, they are generated by the model WETTREG and for Saxony, they are generated by the model WEREX. These OWP are weather patterns of the atmospheric condition concerning temperature and humidity. They do not comprise information of synoptic flow patterns and the mean flow direction. But such information would be required especially for the disaggregation of future precipitation time series. As far as I am aware, there is still no free available dataset of OWPs as used for the present study. The generation of such future OWP datasets is still a complex field of research.
References
Bárdossy A (1998) Generating precipitation time series using simulated annealing. Water Resour Res 34:1737–1744
Beck F, Bárdossy A (2013) Indirect downscaling of hourly precipitation based on atmospheric circulation and temperature. Hydrol Earth Syst Sci 17:4851–4863
Bergström S (1992) The HBV model: its structure and applications. Swedish Meteorological and Hydrological Institute (SMHI), Hydrology, Norrköping
Bissolli P, Dittmann E (2003) The objective weather type classification of the German Weather Service and its possibilities of application to environmental and meteorological investigations. Meteorol Z 10:253–260
Blüthgen J, Weischet W (1980) Lehrbuch der Allgemeinen Geographie, Band 2, Allgemeine Klimageographie. 3, Auflage Walter de Gruyter, Berlin
Burek P, Rademacher S (2007) Operationelle Hochwasservorhersage für die Elbe mit dem Wasserstandsvorhersagesystem WAVOS. In: Fünf Jahre nach der Flut. Hochwasserschutzkonzepte - Planung, Berechnung, Realisierung. Dresdner Wasserbau-kolloquium 2007. Dresdner Wasserbauliche Mitteilungen Heft 35, Technische Universität Dresden, Dresden, pp. 25–34
Debele B, Srinivasan R, Parlange JY (2007) Accuracy evaluation of weather data generation and disaggregation methods at finer timescales. Adv Water Resour 30:1286–1300
Enke W, Schneider F, Deutschlaender T (2005) A novel scheme to derive optimized circulation pattern classifications for downscaling and forecast purposes. Theor Appl Climatol 82:51–63. https://doi.org/10.1007/s00704-004-0116-x
Förster C, Hanzer F, Winter B, Marke T, Strasser U (2016) An open-source MEteoroLOgical observation time series DISaggregation tool (MELODIST v01.1.1). Geosci Model Dev 9:2315–2333
Glasbey CA, Cooper G, McGechan MB (1995) Disaggregation of daily rainfall by conditional simulation from a point-process model. J Hydrol 165:1–9
Güntner A, Olsson J, Calver A, Gannon B (2001) Cascade-based disaggregation of continuous rainfall time series: the influence of climate. Hydrol Earth Syst Sci 5:145–164
Kim Y, Rajagopalan B, Lee GW (2016) Temporal statistical downscaling of precipitation and temperature forecasts using a stochastic weather generator. Adv Atmos Sci 33:175–183
Kreienkamp F, Spekat A, Enke W (2010) Weiterentwicklung von WETTREG bezüglich neuartiger Wetterlagen. Bericht, CEC Potsdam im Auftrag eines Konsortiums aus Landesumweltämtern und dem UBA
Kronenberg R, Franke J, Bernhofer C, Körner P (2015) Detection of potential areas of changing climatic conditions at a regional scale until 2100 for Saxony, Germany. Meteorol Hydrol Water Manage 3(2):17–26
Lee T, Jeong C (2014) Nonparametric statistical temporal downscaling of daily precipitation to hourly precipitation and implications for climate change scenarios. J Hydrol 510:182–196
Lisniak D, Franke J, Bernhofer C (2013) Circulation pattern based parameterization of a multiplicative random cascade for disaggregation of observed and projected daily rainfall time series. Hydrol Earth Syst Sci 17:2487–2500. https://doi.org/10.5194/hess-17-2487-2013
Lu Y, Qin XS, Mandapaka PV (2015) A combined weather generator and K-nearest-neighbour approach for assessing climate change impact on regional rainfall extremes. Int J Climatol 35:4493–4508
McCullagh P, Nelder JA (1989) Generalized linear models, 2nd edn. Chapman and Hall, London
Mezghani A, Hingray B (2009) A combined downscaling-disaggregation weather generator for stochastic generation of multisite hourly weather variables over complex terrain: development and multi-scale validation for the Upper Rhone River basin. J Hydrol 377:245–260
Olsson J (1998) Evaluation of a scaling cascade model for temporal rainfall disaggregation. Hydrol Earth Syst Sci 2:19–30. https://doi.org/10.5194/hess-2-19-1998
Pfützner B, Klöcking B, Becker A (2007) ArcEGMO GIS-gestützte hydrologische Modellierung. BAH – Büro für Angewandte Hydrologie (ed), Berlin und Potsdam
Schulla J, Jasper K (2007) Model description WaSiM-ETH (water balance simulation model ETH). Internal report. Institute for Atmospheric and Climate Science, ETH, Zürich
Schumann A (ed) (2009) Entwicklung integrativer Lösungen für das operationelle Hochwassermanagement am Beispiel der Mulde - Abschlussbericht Verbundvorhaben. Schriftenreihe Hydrologie/Wasserwirtschaft der Ruhr-Universität Bochum, H 23, ISSN 0949-5975
Sharif M, Burn DH, Hofbauer KM (2013) Generation of daily and hourly weather variables for use in climate change vulnerability assessment. Wat Res Man 27:1533–1550
SMUL (ed) (2005) Klimawandel in Sachsen – Sachstand und Ausblick. Sächsisches Staatsministerium für Umwelt und Landwirtschaft. Eigenverlag. SMUL, Dresden
SMUL (ed) (2008) Sachsen im Klimawandel – Eine Analyse. Sächsisches Staatsministerium für Umwelt und Landwirtschaft, Eigenverlag. SMUL, Dresden
Stull RB (2000) Meteorology for scientists and engineers, Second edn. Brooks/Cole, Pacific Grove
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res 106:7183–7192
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix

(left) Normalized root mean square difference [-], normalized standard deviation [-], and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] for the summer half-year (top) and the winter half-year (bottom) at climate station Dresden based on five stations

(left) Normalized root mean square difference [-], normalized standard deviation [-], and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] for the summer half-year (top) and the winter half-year (bottom) at climate station Fichtelberg based on five stations

(left) Normalized root mean square difference [-], normalized standard deviation [-], and correlation [-] of the generated data of T, SD, rH, and WS for Selection 1 (S1) and Selection 2 (S2); (right) the quantiles of the observed and generated precipitation [mm/h] at climate stations Dresden (top) and Fichtelberg (bottom) based on six stations
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Görner, C., Franke, J., Kronenberg, R. et al. Multivariate non-parametric Euclidean distance model for hourly disaggregation of daily climate data. Theor Appl Climatol 143, 241–265 (2021). https://doi.org/10.1007/s00704-020-03426-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-020-03426-7